
Autores: Oriol Catasus, Xavier Oriol i Ernest Teniente
Cuando trabajamos con bases de datos, el escenario ideal es sencillo: primero, estudiamos el dominio; luego, basándonos en esto, definimos la estructura de la base de datos y las restricciones de integridad para que todo funcione a la perfección; finalmente, una vez que tenemos todo diseñado, insertamos los datos en la base de datos, lo que garantiza que estos datos siempre cumplirán con las reglas de integridad que hemos definido.
El problema es que este escenario ideal no siempre es posible. Hoy en día, especialmente en el mundo del Big Data, nos encontramos a menudo con proyectos donde se generan grandes volúmenes de datos no estructurados, sin un esquema claro ni restricciones predefinidas. Y aquí es donde entran en juego los algoritmos que descubren automáticamente restricciones de integridad a partir de los datos.
Qué son las denial constraints (DCs)?
Las Denial Constraints (DCs), o restricciones de denegación, son una forma muy potente y flexible de describir patrones prohibidos en los datos. Su gran ventaja es que pueden expresar restricciones complejas que otros formalismos no pueden.
Por ejemplo, imaginemos una universidad con una política de tasas que garantiza que los estudiantes con mejores notas paguen menos tasas en comparación con otros estudiantes con peores notas, siempre dentro de la misma asignatura. Esta regla es difícil de expresar con mecanismos tradicionales, pero con una DC se puede hacer sin problemas:
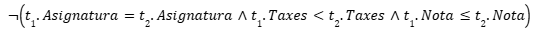
El problema: un alud de restricciones
Debido a su gran expresividad, en los últimos años se han desarrollado varios algoritmos que permiten descubrir las restricciones de integridad en forma de DC a partir de un conjunto de datos. Sin embargo, estos algoritmos presentan un problema evidente que afecta a todos ellos y dificulta su adopción práctica: la enorme cantidad de DCs descubiertas.
En nuestras pruebas hemos podido comprobar cómo conjuntos de datos pequeños con menos de 10 atributos pueden llegar a generar cientos de restricciones, lo que hace inviable cualquier tipo de interpretación de las restricciones descubiertas.
Esto ocurre porque los algoritmos de descubrimiento de DCs generan muchas DCs redundantes, es decir, son restricciones que significan lo mismo pero expresadas con palabras diferentes. En nuestros experimentos hemos visto casos donde hasta el 95% de las DCs descubiertas son redundantes.
Nuestra solución
Esto ocurre porque los algoritmos de descubrimiento de DCs generan muchas DCs redundantes, es decir, son restricciones que significan lo mismo pero expresadas con palabras diferentes. En nuestros experimentos hemos visto casos donde hasta el 95% de las DCs descubiertas son redundantes.
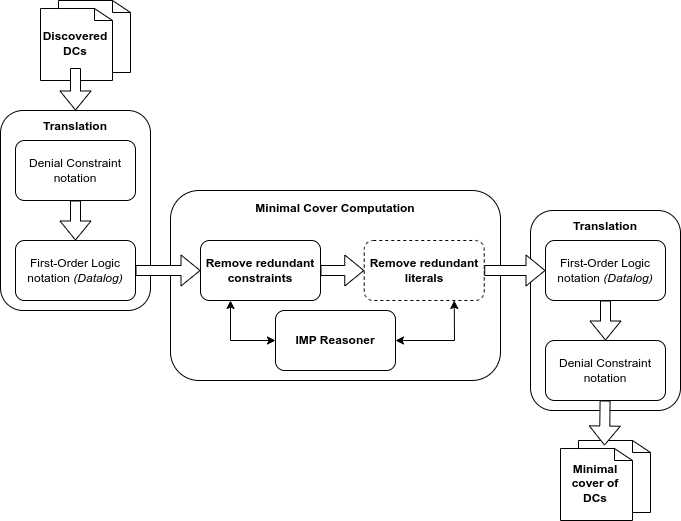
La imagen de abajo muestra un diagrama simplificado de nuestro sistema: toma como entrada las DCs descubiertas por los algoritmos existentes, las traduce a Datalog, las minimiza mediante el IMP Reasoner y luego las vuelve a traducir a notación DC, dando como resultado el conjunto mínimo de las restricciones originales.
Hemos probado este enfoque con diferentes tipos de datos y hemos encontrado que, en todos los experimentos, entre el 70% y el 95% de las restricciones descubiertas eran redundantes y se podían eliminar, pasando de un conjunto inicial de cientos de restricciones a un conjunto mínimo de entre 30 y 60 DCs. Esto permite que el conjunto de DCs resultante sea una herramienta útil en la práctica para que diseñadores y expertos puedan extraer conocimiento y reglas de negocio sobre el dominio.
Como próximos pasos, nos gustaría explorar el desarrollo de nuevas heurísticas para ser capaces de predecir cuándo una DC es probable que sea redundante dado un pequeño subconjunto de las DCs iniciales, lo que mejoraría significativamente la eficiencia de nuestra solución en escenarios donde tenemos miles de restricciones por analizar.