Autors: Oriol Catasus, Xavier Oriol i Ernest Teniente
Quan treballem amb bases de dades, l’escenari ideal és senzill: primer, estudiem el domini; després, en base a aquest, definim l’estructura de la base de dades i les restriccions d’integritat per a que tot funcioni a la perfecció; per últim, un cop ho tenim tot dissenyat, inserim les dades a la base de dades, el que garanteix que aquestes dades sempre compliran amb les regles d’integritat que hem definit.
El problema és que aquest escenari ideal no sempre és possible. Avui dia, especialment en el món del Big Data, ens trobem sovint amb projectes on es generen grans volums de dades desestructurades, sense un esquema clar ni restriccions predefinides. I aquí és on entren en joc els algoritmes que descobreixen automàticament restriccions d’integritat a partir de les dades.
Què són les denial constraints (DCs)?
Les Denial Constraints (DCs), o restriccions de denegació, són una manera molt potent i flexible de descriure patrons prohibits a les dades. El seu gran avantatge és que poden expressar restriccions complexes que altres formalismes no poden.
Per exemple, imaginem una universitat amb una política de taxes que garanteix que els alumnes amb millors notes paguin menys taxes en comparació amb altres alumnes amb pitjors notes, sempre dins de la mateixa assignatura. Aquesta regla és difícil d’expressar amb mecanismes tradicionals, però amb una DC es pot fer sense problemes:
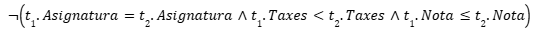
El problema: una allau de restriccions
Degut a la seva gran expressivitat, en els darrers anys s’han desenvolupat diversos algorismes que permeten descobrir les restriccions d’integritat en forma de DC d’un conjunt de dades. Tot i això, aquests algoritmes presenten un problema evident que els afecta a tots ells i dificulta la seva adopció a la pràctica: l’enorme quantitat de DCs descobertes.
En les nostres proves hem pogut comprovar com datasets petits de menys de 10 atributs poden arribar a generar centenars de restriccions, el que fa inviable qualsevol tipus d’interpretació de les restriccions descobertes.
Això es produeix perquè els algorismes de descobriment de DCs generen moltes DCs redundants, és a dir, són restriccions que volen dir el mateix però amb paraules diferents. En els nostres experiments hem vist casos on fins al 95% de les DCs descobertes són redundants.
La nostra solució
Per solucionar-ho, proposem utilitzar un raonador de lògica de primer ordre per detectar quines restriccions són redundants i eliminar-les. Com que són redundants, no aporten informació i per tant es poden eliminar sense problemes.
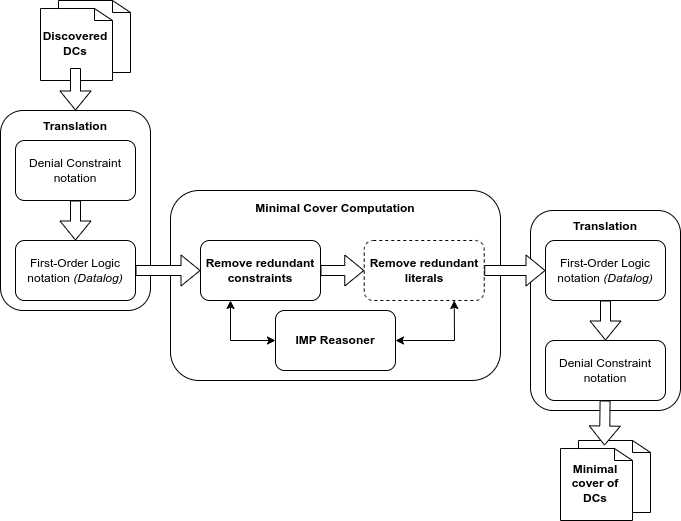
La imatge de sota mostra un diagrama simplificat del nostre sistema: agafa com a input les DCs descobertes pels algorismes existents, les tradueix a Datalog, les minimitza mitjançant el l’IMP Reasoner i les torna a traduir a notació DC, donant com a resultat el conjunt mínim de les restriccions originals.
Hem provat aquest enfoc amb diferents tipologies de dades i hem trobat que, en tots els experiments, entre el 70% i el 95% de les restriccions descobertes eren redundants i es podien eliminar, passant d’un conjunt inicial de centenars de restriccions a un conjunt mínim d’entre 30 i 60 DCs. Això permet que el conjunt de DCs resultants sigui una eina útil a la pràctica per a que dissenyadors i experts puguin extreure coneixement i regles de negoci sobre el domini.
Com a propers passos, ens agradaria explorar el desenvolupament de noves heurístiques per ser capaços de predir quan una DC és probable que sigui redundant donat un subconjunt petit de les DCs inicials, fet que milloraria molt l’eficiència de la nostra solució en escenaris a on tenim milers de restriccions per analitzar.
