
Authors: Oriol Catasus, Xavier Oriol i Ernest Teniente
When working with databases, the ideal scenario is simple: first, we study the domain; then, based on this, we define the database structure and integrity constraints so that everything works perfectly; finally, once everything is designed, we insert the data into the database, which ensures that this data will always comply with the integrity rules we have defined.
The problem is that this ideal scenario is not always possible. Nowadays, especially in the world of Big Data, we often encounter projects where large volumes of unstructured data are generated, without a clear schema or predefined constraints. This is where algorithms that automatically discover integrity constraints from the data come into play.
What are denial constraints (DCs)?
Denial Constraints (DCs) are a very powerful and flexible way to describe prohibited patterns in data. Their main advantage is that they can express complex constraints that other formalisms cannot.
For example, imagine a university with a tuition policy that ensures that students with higher grades pay lower fees compared to other students with lower grades, always within the same course. This rule is difficult to express with traditional mechanisms, but with a DC it can be done without any problem:
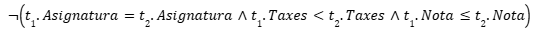
The problem: a flood of constraints
Due to their great expressiveness, in recent years several algorithms have been developed that allow the discovery of integrity constraints in the form of DCs from a dataset. However, these algorithms present an obvious problem that affects all of them and hinders their practical adoption: the enormous number of DCs discovered.
In our tests, we have observed how small datasets with fewer than 10 attributes can generate hundreds of constraints, making any type of interpretation of the discovered constraints unfeasible.
This occurs because DC discovery algorithms generate many redundant DCs, that is, constraints that mean the same thing but are expressed differently. In our experiments, we have seen cases where up to 95% of the discovered DCs are redundant.
Our solution
To address this, we propose using a first-order logic reasoner to detect which constraints are redundant and eliminate them. Since they are redundant, they provide no additional information and can therefore be safely removed.
The image below shows a simplified diagram of our system: it takes as input the DCs discovered by existing algorithms, translates them into Datalog, minimizes them using the IMP Reasoner, and then translates them back into DC notation, resulting in the minimal set of the original constraints.
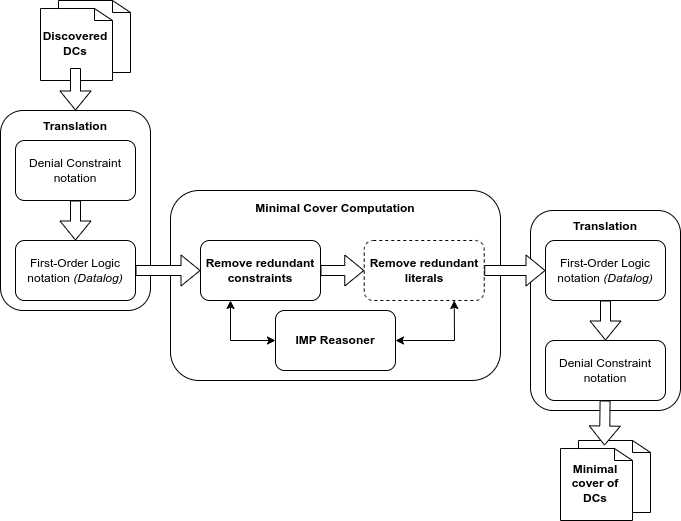
We have tested this approach with different types of data and found that, in all experiments, between 70% and 95% of the discovered constraints were redundant and could be removed, reducing an initial set of hundreds of constraints to a minimal set of between 30 and 60 DCs. This makes the resulting set of DCs a practical tool for designers and experts to extract knowledge and business rules about the domain.
As next steps, we would like to explore the development of new heuristics to be able to predict when a DC is likely to be redundant given a small subset of the initial DCs, which would greatly improve the efficiency of our solution in scenarios where we have thousands of constraints to analyze.