Combinando cuantización, LoRA, FlashAttention-2 y otras optimizaciones para el fine-tuning de modelos LLM en una GPU de consumo.
El entrenamiento de grandes modelos del lenguaje (LLM) modernos está fuertemente limitado por la memoria de la GPU. Aunque los modelos recientes suelen asumir acceso a aceleradores empresariales con entre 40 y 80 GB de VRAM, muchos entornos de investigación e ingeniería dependen de hardware de consumo con límites significativamente más bajos.
En un proyecto reciente en el inLab FIB, exploramos el fine-tuning de modelos pequeños (de cuatro a ocho mil millones de parámetros) como Qwen3-8B, utilizando una única NVIDIA GeForce RTX 4080 con 16 GB de VRAM. El objetivo era la generación de memorias de subvenciones (proyecto FabAI Copilot) que requieren contextos de hasta 140.000 tokens, respetando al mismo tiempo las limitaciones del hardware de consumo.
Conseguirlo no fue posible mediante una única técnica de optimización. En cambio, el flujo de trabajo de entrenamiento combinó diversas estrategias que apuntaban simultáneamente a diferentes fuentes de consumo de VRAM.
Qué pasa con la VRAM durante el entrenamiento?
Una idea errónea común es que los pesos del modelo son el único contribuyente principal al uso de la memoria de la GPU. En la práctica, la memoria de entrenamiento se distribuye entre varios componentes:

El finetuning para contextos largos es especialmente exigente porque la memoria de activación y los cálculos de atención crecen rápidamente con la longitud de la secuencia. Incluso cuando los pesos del modelo caben en memoria, el entrenamiento de secuencias largas puede provocar errores de falta de memoria (Out-Of-Memory, OOM) únicamente a causa de las activaciones.
Reducción de la memoria del modelo
La primera capa de optimización se centró en reducir la huella de memoria persistente del modelo y de los estados de entrenamiento.
Cuantitzación a 4-bit
La primera optimización fue utilizar los pesos del modelo cuantizados con el formato NF4 propio de la librería BitsAndBytes. Esta optimización se realiza desde el principio, ya que normalmente los parámetros del modelo se publican en distintos niveles de precisión, permitiendo a los usuarios elegir entre la capacidad del modelo y la memoria ocupada. Habitualmente, las cuantizaciones están disponibles desde 1 bit hasta 16 bits, siendo la versión de 4 bits la elegida, cuatro veces más pequeña que la original y ofreciendo un buen compromiso de capacidad.
LoRA, RS-LoRA y QLoRA
Low-Rank Adaptation (LoRA) reduce el número de parámetros entrenables introduciendo pequeñas matrices en cada capa del modelo. En la práctica, la modificación de todos los parámetros a menudo es inviable no por los propios pesos, sino porque los gradientes y los estados del optimizador escalan con el número de parámetros.
Se utilizó Rank-Stabilized LoRA (RS-LoRA) y Quantized LoRA (QLoRA) aplicados a todas las proyecciones lineales para mejorar la estabilidad y poder entrenar con cuantizaciones más bajas.
Optimizando el optimizador
Los estados del optimizador pueden consumir cantidades enormes de memoria durante el entrenamiento y, en ocasiones, superan la memoria que requiere el propio modelo. Para mitigarlo, durante el entrenamiento se utilizaron optimizadores cuantizados de 8 bits junto con optimizadores con paginación (paged_adamw_8bit).
Los optimizadores con paginación descargan dinámicamente los estados del optimizador a la RAM del sistema durante los picos de memoria, evitando errores de agotamiento de memoria (OOM) durante el entrenamiento de contextos largos. En la práctica, esto fue especialmente importante durante el entrenamiento cerca de los límites de hardware de la RTX 4080.
Control de la memoria de activación
Aunque la cuantización y LoRA redujeron el uso de memoria estática, el entrenamiento con contextos largos seguía estando dominado por la memoria de activación (activation memory). Por tanto, fueron necesarias diversas optimizaciones adicionales para controlar el crecimiento de los tensores intermedios durante el forward y backward pass.
FlashAttention-2
FlashAttention-2 implementa kernels que ejecutan las funciones de “atención” que requieren las capas Transformer teniendo en cuenta el tráfico de datos, lo que minimiza el uso de VRAM mediante la agrupación eficiente de los cálculos de atención.
Sin núcleos de atención optimizados, las ejecuciones de contextos largos a menudo superaban los límites de memoria debido al comportamiento de escala cuadrática de la atención en la arquitectura Transformer.
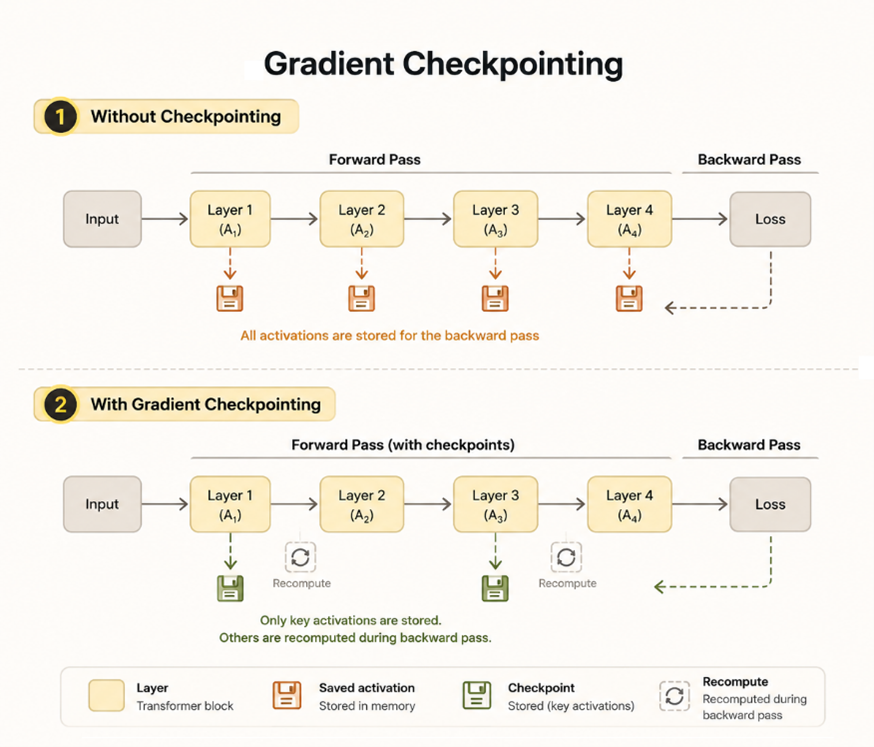
Gradient Checkpointing
El gradient checkpointing reduce la memoria de activación descartando algunas activaciones durante el forward pass y recalculándolas durante el paso inverso en lugar de almacenarlas permanentemente.
Esto introduce un clásico compromiso de ingeniería: un menor uso de memoria a costa de un mayor tiempo de cálculo. No obstante, para contextos largos, la recomputación de activaciones se volvió esencial para mantenerse dentro del presupuesto de 16 GB de VRAM.
Kernel Fusion
El entrenamiento también utilizó kernels Triton fusionados a través del framework Unsloth. Estos núcleos combinan operaciones adyacentes, de forma similar a como funciona FlashAttention, en menos operaciones de GPU.
La reducción de la materialización de tensores intermedios ayudó a disminuir la sobrecarga de activación y a mejorar el rendimiento. En la práctica, sin embargo, los kernels propios de Unsloth no son compatibles con los de Liger-Kernel, lo que obligaba a hacer concesiones entre ambas optimizaciones.
Acumulación de Gradientes
Para controlar aún más el pico de uso de la VRAM, el proceso de entrenamiento utilizó solo una secuencia en cada forward y backward pass, pero en lugar de limitarse a realizar una actualización del optimizador con un solo ejemplo (lo que puede dar lugar a overfitting), se combinó con la acumulación de gradientes (Gradient Accumulation).
Concretamente, en lugar de actualizar los parámetros del modelo después de procesar cada secuencia, los gradientes se calculan de forma incremental y se acumulan en memoria a lo largo de varios pasos, actualizando los pesos con una “dirección” más precisa.
Gestión de contextos largos
Més enllà de les tècniques estàndard d’optimització de LLM, el projecte també va requerir estratègies explícites de gestió de context per donar suport a les càrregues de treball de generació de documents llargs.
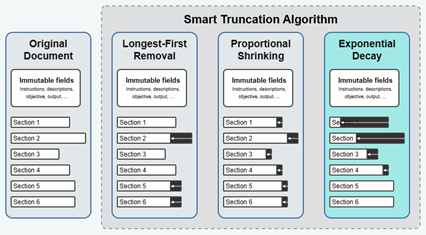
Smart Context Truncation
Se implementó un algoritmo de truncamiento de decaimiento exponencial para mantener una longitud de contexto máxima de 20.000 tokens en cada paso, priorizando la información reciente.
Aunque el documento completo puede acabar teniendo más de 140.000 tokens de longitud, si dividimos inteligentemente este documento, podemos abordar cada sección individualmente y ser mucho más estrictos con el contexto utilizado en cada paso. Esto también puede considerarse una optimización que ofrece una reducción de memoria a cambio de más tiempo de ejecución y cierta pérdida de contexto en algunos casos.
Vocabulary Slicing
Una optimización especialmente eficaz consistió en reducir el tamaño del vocabulario del tokenizador y del modelo de 128k tokens a unos 100k. Esto redujo la memoria necesaria tanto para las capas de embedding como para la capa final del modelo.
Aunque se habla menos de ello que de la cuantización o LoRA, la reducción del vocabulario resultó ser una optimización de nivel de sistema sorprendentemente eficaz bajo estrictas limitaciones de VRAM. Esta reducción es muy efectiva si el LLM final va a funcionar exclusivamente en un conjunto cerrado de idiomas, ya que se pueden eliminar muchos tokens sin impacto en el rendimiento.
Conclusión
El resultado más importante de este trabajo no fue solo la capacidad de realizar el fine-tuning del LLM, sino también la cantidad de conocimiento de ingeniería que surgió de tener que trabajar dentro de este espacio de restricciones.
Trabajar bajo límites estrictos de VRAM cambió fundamentalmente la forma de abordar cada problema. En lugar de confiar en configuraciones de entrenamiento por defecto, cada etapa y cada parámetro de configuración tuvo que cuestionarse, medirse y simplificarse hasta que fuera viable.
Las restricciones no solo dieron forma a la solución, sino también al propio proceso de aprendizaje.