Combinant quantització, LoRA, FlashAttention-2 i altres optimitzacions per al finetuning de models LLM en una GPU de consumidor.
L’entrenament de grans models del llenguatge (LLM) moderns està fortament limitat per la memòria de la GPU. Tot i que els models recents solen assumir accés a acceleradors empresarials amb entre 40 i 80 GB de VRAM, molts entorns de recerca i enginyeria depenen de maquinari de consum amb límits significativament més baixos.
En un projecte recent a l’inLab FIB, vam explorar el finetuning de models petits (de quatre a vuit mil milions de paràmetres) com el Qwen3-8B, utilitzant una única NVIDIA GeForce RTX 4080 amb 16 GB de VRAM. L’objectiu era la generació de memòries de subvencions (projecte FabAI Copilot) que requereixen contextos de fins a 140.000 tokens, tot respectant les limitacions del maquinari de consum.
Aconseguir-ho no va ser possible mitjançant una única tècnica d’optimització. En canvi, el flux de treball d’entrenament va combinar diverses estratègies que apuntaven simultàniament a diferents fonts de consum de VRAM.
Què passa amb la VRAM durant l’entrenament?
Una idea errònia comuna és que els pesos del model són l’únic contribuent principal a l’ús de la memòria de la GPU. En la pràctica, la memòria d’entrenament es distribueix entre diversos components:

El finetuning per a contextos llargs és especialment exigent perquè la memòria d’activació i els càlculs d’atenció creixen ràpidament amb la longitud de la seqüència. Fins i tot quan els pesos del model caben a la memòria, l’entrenament de seqüències llargues pot provocar errors per excés de memòria (Out-Of-Memory, OOM) només a causa de les activacions.
Reducció de la memòria del model
La primera capa d’optimització es va centrar a reduir la petjada de memòria persistent del model i dels estats d’entrenament.
Quantització a 4-bit
La primera optimització va ser utilitzar els pesos del model quantitzats amb el format NF4 propi de la llibreria BitsAndBytes. Aquesta optimització es fa des del principi, ja que normalment es publiquen els paràmetres del model en diferents nivells de precisió, permitent als usuaris triar escollir entre intel·ligència del model i memòria ocupada. Normalment, les quantitzacions estan disponibles des d’1 bit fins a 16 bits, sent la versió de 4 bits escollida, quatre vegades més petita que l’original i oferint un bon compromís d’intel·ligència.
LoRA, RS-LoRA i QLoRA
Low-Rank Adaptation (LoRA) redueix el nombre de paràmetres entrenables introduint petites matrius a cada capa del model. A la pràctica, la modificació de tots els paràmetres sovint és inviable no pas pels mateixos pesos, sinó perquè els gradients i els estats de l’optimitzador escalen amb el nombre de paràmetres.
Es va utilitzar Rank-Stabilized LoRA (RS-LoRA) i Quantized LoRA (QLoRA) aplicat a totes les projeccions lineals per millorar l’estabilitat i poder entrenar en quantitzacions més baixes.
Optimitzant l’optimitzador
Els estats de l’optimitzador poden consumir quantitats enormes de memòria durant l’entrenament, i de vegades superen la memòria que requereix el mateix model. Per mitigar-ho, durant l’entrenament es va utilitzar optimitzador quantitzats de 8 bits juntament amb paged optimizers (paged_adamw_8bit).
Els paged optimizers descarreguen dinàmicament els estats de l’optimitzador a la RAM del sistema durant els pics de memòria, evitant errors d’esgotament de la memòria (OOM) durant l’entrenament de contextos llargs. A la pràctica, això va ser especialment important durant l’entrenament a prop dels límits de maquinari de la RTX 4080.
Control de la memòria d’activació
Tot i que la quantificació i LoRA van reduir l’ús de memòria estàtica, l’entrenament amb contextos llargs continuava dominat per la memòria d’activació (activation memory). Per tant, van ser necessàries diverses optimitzacions addicionals per controlar el creixement dels tensors intermedis durant el forward i backward pass.
FlashAttention-2
FlashAttention-2 implementa kernels que implementen les funcions “d’atenció” que requereixen les capes de Transformer tenint en compte el trànsit de les dades que minimitzen la reserva de VRAM mitjançant l’agrupació eficient dels càlculs d’atenció.
Sense nuclis d’atenció optimitzats, les execucions de context llarg sovint superaven els límits de memòria a causa del comportament d’escala quàdrica de l’atenció de l’arquitectura Transformer.
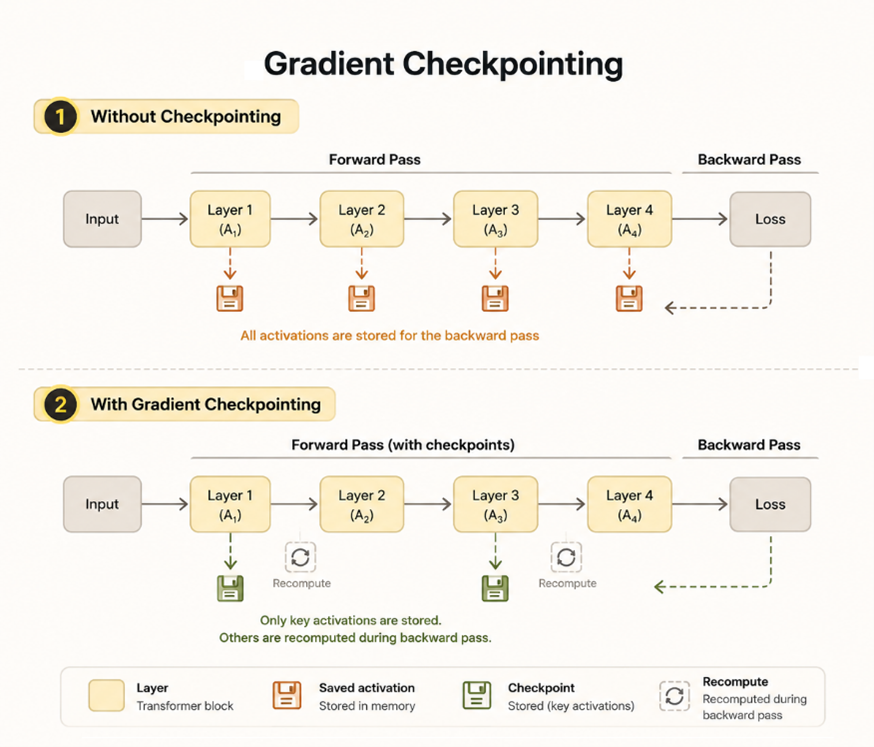
Gradient Checkpointing
Gradient checkpointing redueix la memòria d’activació descartant algunes activacions durant el forward pass i recalculant-les durant el pas invers en lloc d’emmagatzemar-les permanentment.
Això introdueix un clàssic compromís d’enginyeria: un menor ús de memòria a costa d’un temps de càlcul addicional. No obstant això, per a contextos llargs, la recomputació d’activacions es va tornar essencial per mantenir-se dins del pressupost de 16 GB de VRAM.
Kernel Fusion
L’entrenament també va fer servir kernels Triton fusionats a través del framework Unsloth. Aquests nuclis combinen operacions adjacents, similar a com funciona el FlashAttention, en menys operacions de GPU.
La reducció de la materialització de tensors intermedis va ajudar a disminuir la sobrecàrrega d’activació i a millorar el rendiment. A la pràctica, però, els kernels propis de Unsloth no són compatibles amb els de Liger-Kernel, la qual cosa obligava a fer concessions entre aquestes dues optimitzacions.
Acumulació de Gradients
Per controlar encara més el pic d’ús de la VRAM, el procés d’entrenament va utilitzar només una seqüència a cada backward i forward pass, però en comptes de limitar-nos a fer una actualització de l’optimitzador amb un sol exemple (pot donar lloc a overfitting), es va combinar amb l’acumulació de gradients (Gradient Accumulation).
Concretament, en lloc d’actualitzar els paràmetres del model després de processar cada seqüència, els gradients es calculen de manera incremental i s’agreguen en memòria al llarg de diversos passos i actualitzar els pesos amb una “direcció” més precisa.
Gestió de contextos llargs
Més enllà de les tècniques estàndard d’optimització de LLM, el projecte també va requerir estratègies explícites de gestió de context per donar suport a les càrregues de treball de generació de documents llargs.
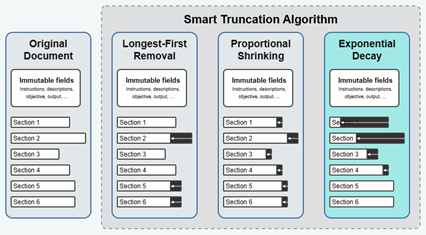
Smart Context Truncation
Es va implementar un algorisme de truncament de decadència exponencial per mantenir una longitud de context màxima de 20.000 tokens en cada pas, tot prioritzant la informació recent.
Tot i que el document sencer pot acabar tenint més de 140.000 tokens de llargada, si dividim intel·ligentment aquest document, podem atacar cada secció individualment i així ser molt més estrictes amb el context que s’utilitza a cada pas. Aquesta també es pot considerar una optimització que ofereix una reducció de memòria a canvi de més temps d’execució i pèrdua de context en algun cas.
Vocabulary Slicing
Una optimització especialment eficaç va consistir a reduir la mida del vocabulari del tokenitzador i del model de 128k tokens a uns 100k. Això va reduir la memòria necessària tant per a les capes d’embedding com per a la capa final del model.
Tot i que se’n parla menys que de la quantificació o la LoRA, la reducció de vocabulari va resultar ser una optimització de nivell de sistema sorprenentment eficaç sota estrictes limitacions de VRAM. Aquesta reducció és molt eficaç si el LLM final funcionarà exclusivament en un conjunt tancat d’idiomes, ja que es poden eliminar molts tokens sense cap impacte en el rendiment.
Conclusion
El resultat més important d’aquest treball no va ser només la capacitat de realitzar el finetuning del LLM, sinó també la quantitat de coneixement d’enginyeria que va sorgir d’haver de treballar dins d’aquest espai de restriccions.
Treballar sota límits estrictes de VRAM va canviar fonamentalment la manera d’abordar cada problema. En lloc de confiar en configuracions d’entrenament per defecte, cada etapa i cada paràmetre de configuració es va haver de qüestionar, mesurar i simplificar fins que va ser factible.
Les restriccions no només van donar forma a la solució, sinó que van donar forma al mateix procés d’aprenentatge.