Esta «ciencia de los datos», nacida del método científico, es la evolución de lo que hasta ahora se conocía como Analista de datos, pero a diferencia de éste que sólo se dedicaba a analizar fuentes de datos de una única fuente, el Data Scientist debe explorar y analizar datos de múltiples fuentes, a menudo inmensas (conocidas como Big Data), y que pueden tener formatos muy diferentes.
Un Data Scientist es un experto en Data Science (Ciencia de datos), su trabajo consiste en extraer conocimiento a partir de los datos para poder responder a las preguntas que se le formulan.
¿Qué es la «ciencia de datos»?
Esta «ciencia de los datos», nacida del método científico, es la evolución de lo que hasta ahora se conocía como Analista de datos, pero a diferencia de éste que sólo se dedicaba a analizar fuentes de datos de una única fuente, el Data Scientist debe explorar y analizar datos de múltiples fuentes, a menudo inmensas (conocidas como Big Data), y que pueden tener formatos muy diferentes. Además, debe tener una fuerte visión de negocio para ser capaz de extraer y transmitir recomendaciones a los responsables de negocio de su empresa.
Estos conjuntos de datos pueden provenir de los datos generados por todo tipo de dispositivos electrónicos (como un móvil, todo tipo de sensores, secuenciadores de genoma, …), redes sociales, datos médicos, páginas web, … y afectan de manera muy significativa la investigación actual en muchos campos como las ciencias biológicas, la informática médica, la salud, las ciencias sociales, por citar sólo algunos.
¿Qué proceso sigue un Data scientist?
El proceso que sigue un Data Scientist para responder a las cuestiones que se le plantean se pueden resumir en estos 5 pasos:
- Extraer los datos, independientemente de su fuente (webs, csv, logs, APIs, etc.) y de su volumen (Big Data o Small Data).
- Limpiar los datos, para eliminar lo que distorsiona las mismas.
- Procesar los datos usando diferentes métodos estadísticos (inferencia estadística, modelos de regresión, pruebas de hipótesis, etc.).
- Diseñar nuevos tests o experimentos en caso necesario.
- Visualizar y presentar gráficamente los datos.
¿Qué se espera de un Data Scientist?
Lo que se espera de un Data Scientist es que no sólo sea capaz de abordar un problema de explotación de datos desde el punto de vista de análisis, sino que también tenga las aptitudes necesarias para cubrir la etapa de gestión de datos. Así, el objetivo de un perfil de este tipo es acercar dos mundos (el de gestión y análisis de datos), que hasta ahora habían podido existir separados, pero que debido a los nuevos requisitos de volumen, de variedad de datos y de velocidad en la explotación de estas (ie, las tres V’s de la definición estándar del término Big Data), se ha vuelto imprescindible llevar a cabo esta explotación a través de un perfil combinado, y que además, también entienda el negocio para dirigir esta explotación hacia resultados que puedan ser de interés para la compañía.
¿Qué perfil debe tener un Data Scientist?
El perfil del Data Scientist, es en cierto modo, como una poción mágica, requiere como ingredientes principales habilidades avanzadas en informática, matemáticas/estadística, aprendizaje automático, pasión por los datos, saber manejar grandes volúmenes de datos, curiosidad, capacidad de comunicar el conocimiento que hemos extraído de los datos, visión de negocio, etc.
Como ya intuía, hay que aprender muchas cosas, ya que la «ciencia de datos» es multidisciplinar, y es una especialización vez exigente y avanzada, pero la combinación es muy potente y difícil de encontrar, tal vez es por eso que la revista Harvard Business Review la definió como el trabajo más Sexy del siglo 21.
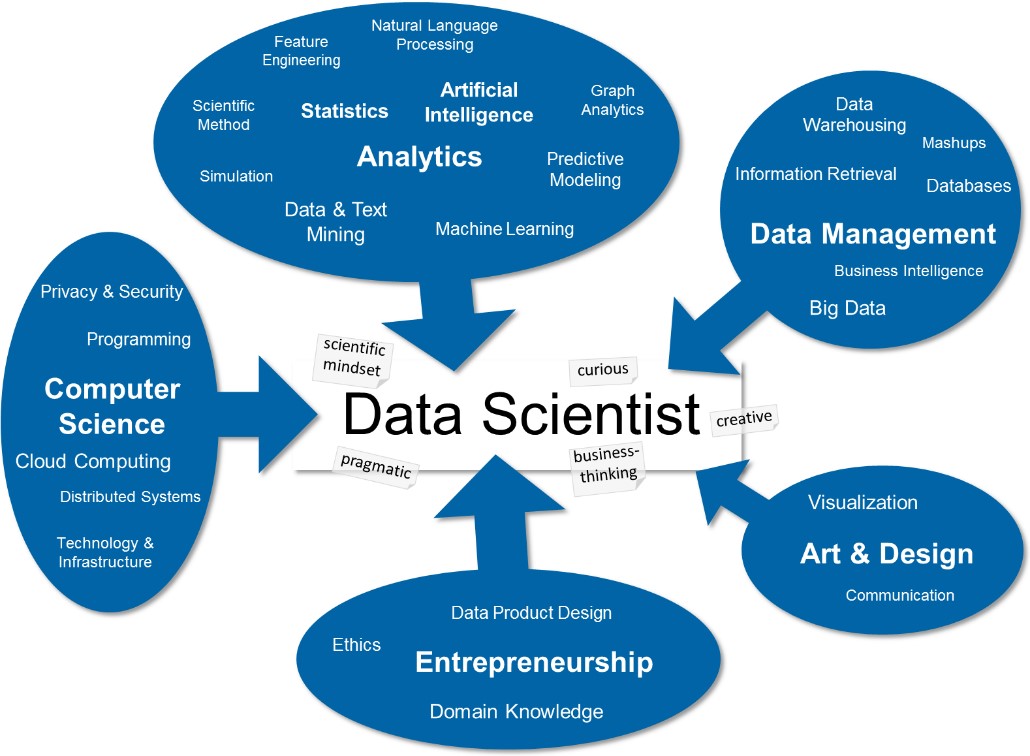
En el diagrama que encabeza el artículo, extraído de Applied Data Science in Europe publicado en la Zurich University of Applied Sciences y el blog d’un dels seus autors, en Thilo Stadelmann, se detallan las diferentes habilidades que debería tener un buen Data Scientist.
¿Qué retos podemos abordar?
Por citar sólo un ejemplo, uno de los retos de las tecnologías actuales de Big Data y Data Science es su aplicación en el análisis de la cantidad ingente de información genómica de que disponemos, y que sirve para estudiar enfermedades como el cáncer.
Piense que los humanos, que tenemos 23 pares de cromosomas, cada uno se compone por unos 3.200 millones de pares de bases de ADN que contienen unos 20.000 a 25.000 genes. Determinar qué combinación de estos genes son significativos para ciertas enfermedades abre la puerta a pensar que puede ser que algún día tengamos una medicina personalizada.
Actualmente existen un montón de fuentes de datos abiertos (Open Data) que podemos analizar, como por ejemplo, los datos abiertos del ayuntamiento de Barcelona o si queremos big data, las del Proyecto del Genoma del Cáncer Pediátrico de la Universidad de Washington, del Hospital Infantil St. Jude, que ha puesto a disposición de todos los datos completos del genoma del cáncer humano.
Si el tema os motiva, podeis participar en diferentes retos de Data Science, como por ejemplo: Identificar signos de retinopatía diabética en imágenes del ojo. Este y otros retos, se publican, por ejemplo las competiciones de kaggle, donde si sois buenos, podeis conseguir unas buenas recompensas.
¿Como puedo aprender?
Una buena manera de aprender Data Science, es mediante la especialización en la plataforma de MOOC (cursos online) Coursera, desde donde se ofrecen los nueve cursos que componen esta especialización de manera gratuita.
En el inLab FIB hace muchos años que trabajamos en el Análisis de datos, en ámbitos como la modelización, la simulación, la optimización, la toma de decisiones y el análisis del aprendizaje (Learning Analytics). Con la aparición de las tecnologías para tratar grandes volúmenes de datos (Big Data) ahora disponemos de herramientas muy potentes que complementan este ámbito.