
Data integration is an area of research with a multitude of applications such as in the business world (e.g., to provide access to legacy systems or external services), science (e.g., to combine information from the hundreds of existing biomedical databases), or on the Web (e.g., to build a platform for analysis and comparison of product prices). All of these examples require the development of a system capable of modeling multiple autonomous data sources, and providing a uniform query interface over them. A classic solution to this problem is the use of a federated database as shown in the following figure. This system is composed of different modules in charge of homogenizing, through wrappers, the data coming from a variety of databases. The user can execute queries (e.g., using SQL) on a global schema and the system, through the mediators, automatically rewrites this into a set of subqueries on each of the databases, and composes the partial results to give an integrated view. This gives the user the perception that he/she is interacting with a single database and not a federation of databases.
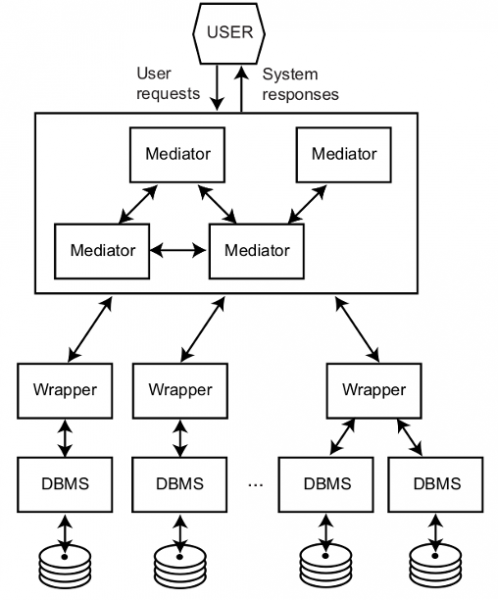
Mediator/*Wrapper Architecture (source, Principles of Distributed Database Systems)
In practice, few systems exist offering these functionalities, and most of them are focused on the mediation of relational databases. Despite this, organizations today want to analyze and enrich their data with external data sources such as these that can be found in open data portals or downloadable via APIs. My doctoral dissertation, which has recently received the SISTEDES award, the company is based on this premise and follows a line of research in the development of flexible and efficient data integration systems to manage the challenges presented when working with large volumes of data and with a great variety (Big Date).
In this post I will summarize two of the contributions resulting from a work carried out in astutely between UPC and ULB from 2015 to 2019, and led by professors Alberto Abelló (UPC), Oscar Romero (UPC) and Stijn Vansummeren (ULB).
Bolster: a reference software architecture for Big Data systems
The foundation for data integration is metadata. These are the data describing the integration system (the global schema, the schema of the sources, the relationships between them, etc.). Relational database management systems incorporate metadata management, but this is not true for modern mass data processing systems. These are characterized to be composed of independent components (those usually known as NOSQL, e.g., Hadoop, Spark, or MongoDB), which generally operate in isolation. The definition of a system architecture that includes these components, and the data extraction, transformation and loading processes is the responsibility of the system administrators.
To make it easier for organizations to adopt this type of technology, we introduced Bolster (see figure below), a software reference architecture (SRA) for Big Data systems. An SRA can be considered as a blueprint describing a set of software components and their relationships. Each of these components can be instantiated with a tool from the Apache ecosystem, or Amazon Web Services (AWS). One of Bolster’s contributions is the incorporation of a semantic layer, which aims to store and serve the metadata needed to automate data communication between components.
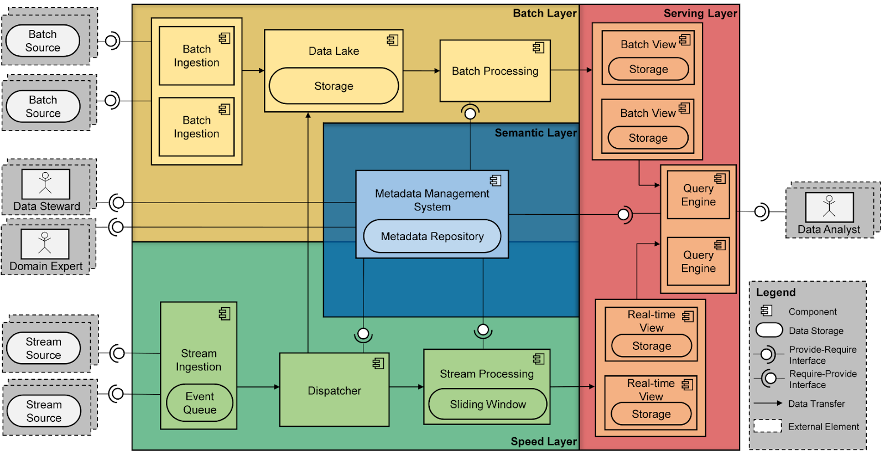
Bolster has been implemented in multiple projects in collaboration with industry. The most relevant example is Las Moiras de AdQore’s project, which made it possible to automate AdQuiver’s data governance protocol.
ODIN: automatic extraction, integration and querying of heterogeneous data sources
Once we have a deployed architecture, it is necessary to generate the necessary metadata to perform the data integration (the information that is stored in the semantic layer). In this thesis we focus on environments with hundreds of data sources and serving data in different formats (e.g. JSON, CSV, XML, etc.). In these situations, manual maintenance of metadata is unfeasible and must be performed automatically.
The ODIN (Where-Demand Data Integration) project aims to automate the metadata extraction and integration process in order to perform federated queries. ODIN represents all metadata as a network to facilitate interoperability (i.e., a query is represented as a subgraph of a network). The ODIN life cycle (see figure below) is divided into three phases:
- Extraction of the schema of the data sources to a network, where the source graphs that model the physical structure of the sources are generated.
- Automatic integration of different sources, based on alignments discovered automatically with the support of a domain expert.
- Execution of federated queries, where a global network query is translated into a set of source queries and the partial results are composed (using join and join operations).
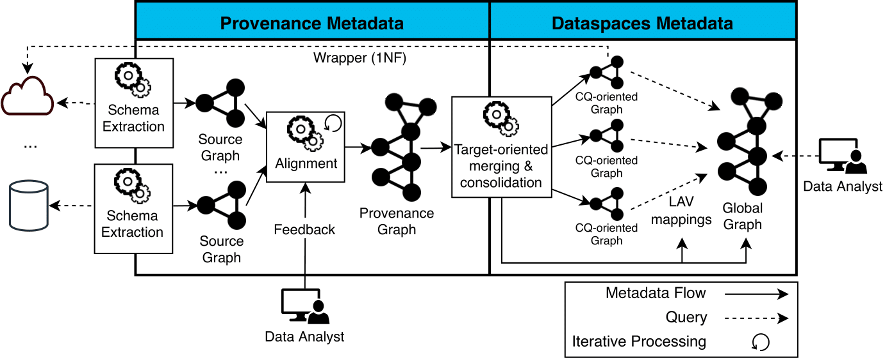
ODIN is a project that goes beyond my doctoral thesis, and where there are many research opportunities. One example is the An Automatic Data Discovery Approach to Enhance Barcelona’s Data Ecosystem, which focuses on the phase of discovering relationships (alignments) between data sources focused on the data ecosystem of the city of Barcelona, or the system NextiaJD led by PhD student Javier Flores.
More information
The complete thesis is available at tdx.cat. In the following articles you can find details on the topics explained in this post: