
La integración de datos es una área de investigación con multitud de aplicaciones como por ejemplo en el mundo empresarial (p. ej., para dar acceso a sistemas legacy o a servicios externos), ciencia (p. ej., para combinar información de los centenares de bases de datos biomédicas existentes), o bien en la Web (p. ej., para construir una plataforma de análisis y comparación de precios de productos). Todos estos ejemplos requieren el desarrollo de un sistema capaz de modelar múltiples fuentes de datos autónomos, y proporcionar una interfaz de consultas uniforme sobre estas. Una solución clásica a este problema es el uso de una base de datos federada cómo se muestra en la siguiente figura. Este sistema está compuesto por diferentes módulos encargados de homogeneizar, a través de los wrappers, los datos provenientes de una variedad de bases de datos. El usuario puede ejecutar consultas (p. ej., usando SQL) sobre un esquema global y el sistema, a través de los mediators, se encarga automáticamente de reescribir esta en un conjunto de subconsultas sobre cada una de las bases de datos, y componer los resultados parciales para dar una visión integrada. Esto da al usuario la percepción de que interactúa con una única base de datos y no una federación de estas.
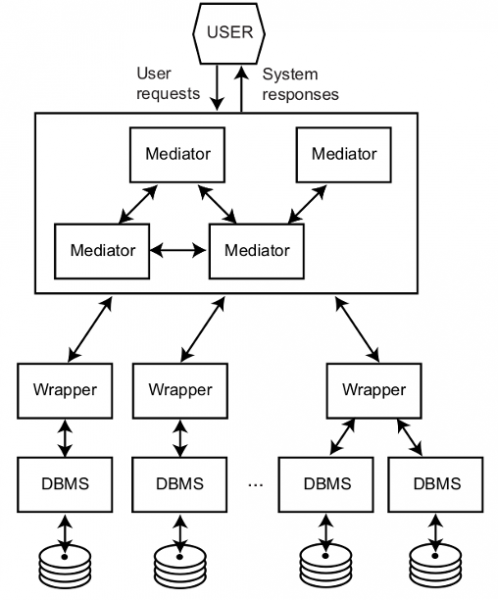
Arquitectura Mediator/*Wrapper (fuente, Principles of Distributed Database Systems)
A la práctica pocos sistemas existen ofreciendo estas funcionalidades, y mayoritariamente están centrados en la mediación de bases de datos relacionales. A pesar de esto, hoy en día las organizaciones quieren analizar y enriquecer sus datos con fuentes de datos externos como por ejemplo estas que se pueden encontrar en portales de datos abiertos o descargables mediante APIs. Mi tesis doctoral, la cual recientemente ha recibido el premio SISTEDES, parte de esta premisa y sigue una línea de investigación en el desarrollo de sistemas de integración de datos flexibles y eficientes para gestionar los retos presentados cuando trabajamos con grandes volúmenes de datos y con una gran variedad (Big Data).
En este post resumiré dos de las contribuciones resultantes de un trabajo llevado a cabo en cotutela entre UPC y ULB de 2015 a 2019, y dirigido por los profesores Alberto Abelló (UPC), Oscar Romero (UPC) y Stijn Vansummeren (ULB).
Bolster: una arquitectura software de referencia para sistemas Big Data
Los cimientos para poder realizar integración de datos son los metadatos. Estas son los datos que describen el sistema de integración (el esquema global, el esquema de las fuentes, las relaciones entre estos, etc.). Los sistemas gestores de bases de datos relacionales incorporan la gestión de metadatos, pero esto no es cierto por el caso de los sistemas modernos de procesamiento de datos masivos. Estos se caracterizan para estar compuestos de componentes independientes (aquellos conocidos normalmente como NOSQL, p. ej., Hadoop, Spark, o MongoDB), que generalmente funcionan de forma aislada. La definición de una arquitectura de sistema que incluya estos componentes, y los procesos de extracción, transformación y carga de datos es una tarea de responsabilidad de los administradores del sistema.
Para facilitar a las organizaciones la tarea de adoptar este tipo de tecnologías, introdujimos Bolster (ver la figura siguiente), una arquitectura software de referencia (SRA) para sistemas Big Data. Una SRA se puede considerar como un plano donde se describen un conjunto de componentes software y sus relaciones. Cada uno de estos componentes se puede instanciar con una herramienta del ecosistema Apache, o Amazon Web Services (AWS). Una de las contribuciones de Bolster es la incorporación de una capa semántica, la cual tiene el objetivo de almacenar y servir los metadatos necesarios para automatizar la comunicación de datos entre componentes.
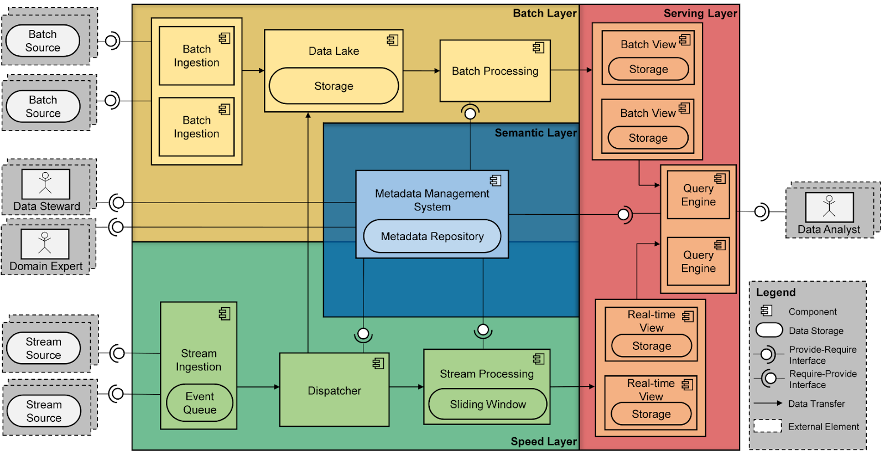
Bolster se ha puesto en práctica en múltiples proyectos en colaboración con la industria. El ejemplo más relevante es el proyecto Las Moiras de AdQore, el cual permitió automatizar el protocolo de gobernanza de datos de AdQuiver.
ODIN: extracción, integración y consulta automática de fuentes de datos heterogéneos
Una vez disponemos de una arquitectura desplegada, es necesario generar los metadatos necesarios para realizar la integración de datos (aquella información que se guarda a la capa semántica). En esta tesis nos centramos en entornos con centenares de fuentes de datos y sirviendo datos en formatos diferentes (p. ej., JSON, CSV, XML, etc.). En estas situaciones el mantenimiento manual de los metadatos es inviable y se tiene que realizar de forma automática.
El proyecto ODIN (On-Demand Data Integration) tiene como objetivo automatizar el proceso de extracción e integración de metadatos para poder realizar consultas federadas. ODIN representa todos los metadatos como grafo para facilitar su interoperabilidad (p. ej., una consulta se representa como un subgraf de un grafo). El ciclo de vida de ODIN (ver la siguiente figura) está dividido en tres fases:
- Extracción del esquema de las fuentes de datos a grafo, donde se generan los source graphs que modelan la estructura física de las fuentes.
- Integración de diferentes fuentes automática, a partir de alineamientos descubiertos automáticamente con el apoyo de un experto en el dominio.
- Ejecución de consultas federadas, donde se traduce una consulta sobre el grafo global a un conjunto de consultas sobre las fuentes y los resultados parciales se componen (usando operaciones de unión y join).
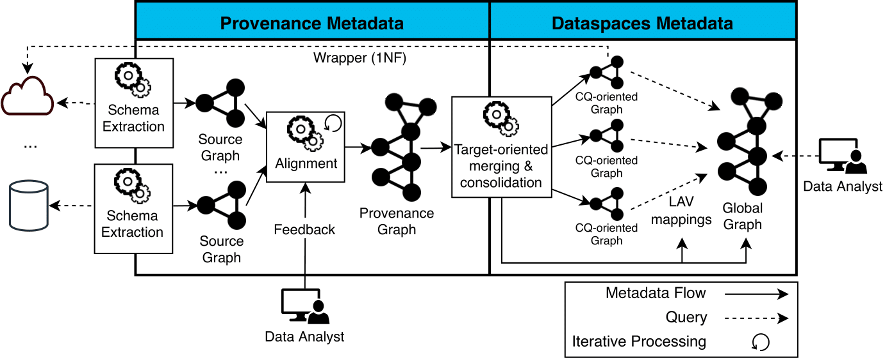
ODIN es un proyecto que va más allá de mi tesis doctoral, y dónde hay muchas oportunidades de investigación. Un ejemplo es el proyecto An Automatic Data Discovery Approach to Enhance Barcelona’s Data Ecosystem, el cual se centra en la fase de descubrir relaciones (alineamientos) entre fuentes de datos enfocado en el ecosistema de datos de la ciudad de Barcelona, o bien el sistema NextiaJD liderado por el estudiante de doctorado Javier Flores.
Más información
La tesis completa está disponible en tdx.cat. En los siguientes artículos podréis encontrar detalles sobre los temas explicados en este post: