Since the creation of the Internet and increasingly, we have had data generated by many applications and we have within reach waiting to be used. Once, having and consuming all this enormous material could become a task virtually impossible or unfeasible both economically and technologically.
Introduction
Since the creation of the Internet and increasingly, we have had data generated by many applications and we have within reach waiting to be used. Having and consuming all this enormous material could become a task virtually impossible or unfeasible both economically and technologically.This limited the use of information to the one that was most relevant. Let’s see what tools we can initiate us to overcome this handicap and get the most value to our data. Open-source tools that anyone has at their disposal. The Hadoop ecosystem.
Hardware
 Today we have at our disposal the power to consume this information without having to have an expensive supercomputer in our store. We can do tests with 8-16GB of RAM and a few GB of hard drive.In a production environment, “commodity hardware” is used, machines that do not need to have a high degree of reliability and sophistication (RAID systems, enterprise hard drives, redundant components, etc.). Machines of this type are much cheaper and if they break, we put others and that’s it. The weight of reliability lies with the software. We will, however, have to dimension the characteristics according to the requirements of our scenario. A typical configuration of a node in a productive environment could be a machine with 8-24 cores, 32-256GB of RAM and about 8-12 HDD disks.
Today we have at our disposal the power to consume this information without having to have an expensive supercomputer in our store. We can do tests with 8-16GB of RAM and a few GB of hard drive.In a production environment, “commodity hardware” is used, machines that do not need to have a high degree of reliability and sophistication (RAID systems, enterprise hard drives, redundant components, etc.). Machines of this type are much cheaper and if they break, we put others and that’s it. The weight of reliability lies with the software. We will, however, have to dimension the characteristics according to the requirements of our scenario. A typical configuration of a node in a productive environment could be a machine with 8-24 cores, 32-256GB of RAM and about 8-12 HDD disks.
To introduce ourselves in the use of this software, it is not necessary to have a cluster of powerful machines, we can use a Cubieboard cluster 🙂 ?, a simple VM’s in our PC or with some VM like Cloudera QuickStart VM with everything already Mounted, which its just for learning.
Motivation

First of all, let’s make one thing clear and let’s not fool ourselves, Big Data is to deal with large volumes of data. Big Data appears when we decide to stop getting only what is more relevant and beginning to get EVERYTHING. All information is useful at some point and can allow us to see things that only with the “important” we can not get to see and that in many occasions can bring us much value.
As we said, nowadays it has become feasible to have a lot of information and be able to consume it, but you also have to understand when it makes sense to use Big Data tools and when not. If we have a high volume of data and we have to deal with gigas and gigas of data (or some larger magnitude) it would be useful to use these tools. If not, we can also make use of all this, but killing flies to gunshots is perhaps not so suitable, even if it is fashion.
The Base
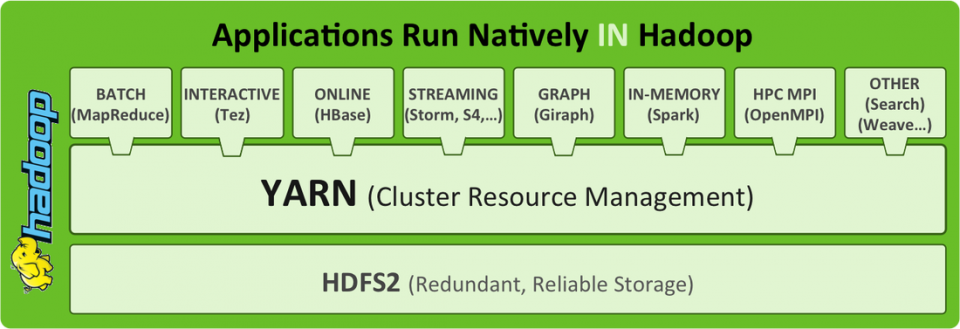
Talking about Big Data is talking about Hadoop and everything around it. Let’s see what Hadoop is. Hadoop is based on how it stores and accesses the data. Hadoop is made up of HDFS and MapReduce. The combination of these two allows the data to be replicated and distributed by N nodes benefiting the capacity of access to large volumes. When we want to execute some operation on this distributed data, Hadoop is in charge of processing each portion of the data in the node that contains them. In this way, the locality takes advantage of having the data near where they are going to be processed and allows to scale of almost linear form. If we want to grow in capacity, we add more nodes and go. Storage is handled by HDFS and MapReduce processing.
Basic Complements
With HDFS and MapReduce we have the basic capacity to store raw data and perform processes in parallel, abstracting ourselves from the complexity of this type of computation. Now, we can use other tools on top of Hadoop that enhance these capabilities. Everything will depend on our needs. These are the two most typical:
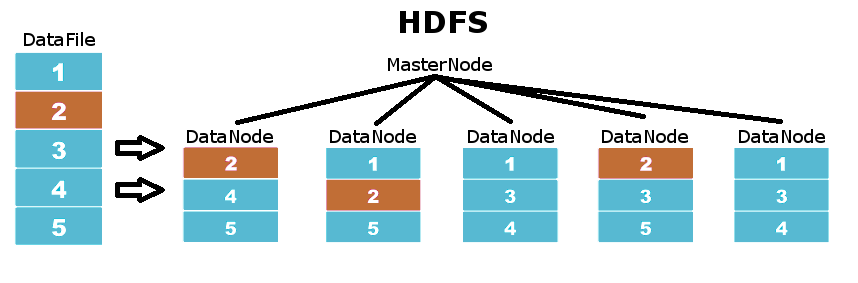
HDFS
It is the filesystem on which Hadoop is based. This file system is based on a master-slave architecture where MasterNodes coordinate DataNodes, which are those where the information is stored. Data in HDFS is distributed by the different DataNodes into partitions of the original file, ensuring that each of these partitions is replicated at a defined replication level. Therefore, we do not need to have systems with RAID, if a disk is damaged, HDFS automatically replicates very quickly all the partitions that were on this disk in all the rest of DataNodes.
YARN – MapReduce
YARN is the evolution of MapReduce for Hadoop 2.0. The function of YARN in Hadoop is to provide an environment that manages the resources to perform computer work. YARN is responsible for distributing the work to be done taking into account where the data to be processed, in addition to managing the own executions of the programs. With YARN we can separate the file system from the execution system. So we can use HDFS without going through YARN or use this resource manager to run applications (as is the case with most tools that work in Hadoop).
HBase
![]() It can be considered “the database” of Hadoop. Based on Google’s BigTable, it provides the ability to create tables with millions of entries and allows read / write access quickly and consistently. It is also versioned and non-relational, so it offers flexibility. It is also easily connectable, either through its java API or through web services. We can use HBase to shape our data.
It can be considered “the database” of Hadoop. Based on Google’s BigTable, it provides the ability to create tables with millions of entries and allows read / write access quickly and consistently. It is also versioned and non-relational, so it offers flexibility. It is also easily connectable, either through its java API or through web services. We can use HBase to shape our data.
Hive
![]() It’s a mix between MapReduce and HBase. It allows to structure the data in tables and views and allows us to make all kinds of queries using its SQL type querying language, HiveQL. For those cases where we can not get what we want with HiveQL, we can connect Hive with our own mappers and reducers, since Hive is very flexible in connectivity and can connect anything.
It’s a mix between MapReduce and HBase. It allows to structure the data in tables and views and allows us to make all kinds of queries using its SQL type querying language, HiveQL. For those cases where we can not get what we want with HiveQL, we can connect Hive with our own mappers and reducers, since Hive is very flexible in connectivity and can connect anything.
Spark
![]() It is the king who has come to conquer them all. While MapReduce performs its processes on disk, Spark loads data into memory and performs operations between intermediate datasets called RDDs. This makes your performance brutal. It is also quite simple to use and has support for both Scala and Java and Python, with libraries for micro-batch (STREAMING), machine learning (MLLIB), graphs (GRAPH) and SQL (SPARKSQL).
It is the king who has come to conquer them all. While MapReduce performs its processes on disk, Spark loads data into memory and performs operations between intermediate datasets called RDDs. This makes your performance brutal. It is also quite simple to use and has support for both Scala and Java and Python, with libraries for micro-batch (STREAMING), machine learning (MLLIB), graphs (GRAPH) and SQL (SPARKSQL).
Other Complements
In addition to the typical suite we have seen, there are many other products that work together with Hadoop and allow new features. Depending on the type of application we will use one or the other. There are also variants of these tools adapted to specific uses, such as SparkOnHBase, Spork, RHadoop and many others. Here is a minuscule classification:
Data Engineering: Spark, Hive, Pig
Data Discovery & Analytics: Spark, Impala, Solr
Data Integration & Storage: HBase, Kudu, HDFS
Unified Data Services: Yarn, Sentry, Hue, Oozie
Data Ingestion: Sqoop, Flume, Kafka
Hands on
We have seen only a brushstroke of the tools that are used for BigData. Mastering them is a matter of hours and practice. To practice, you can make use of the VM that I told you before to put into practice some of the many courses and tutorials that can be found online, which will teach you from the classic WordCount To perform more complex Analytics tasks. I also highly recommend taking advantage of the classic O’Reilly books specific to each technology.