In the 90s, when the WWW appeared, resources were published on the Internet by uploading files directly to a server via FTP and, if the server had all the necessary dependencies configured by the system administrator, the web became accessible. What seemed like a marvel during those years, became a very complex task as the software evolved and the years went by. More dependencies, more frameworks and many configurations that had to be moved to run a certain service. The expression ” It works on my machine” became popular among developers and operations people had a lot of dependency problems to deploy these new versions of the applications.
To solve this problem, in 2013 Docker and container technology was introduced, a lighter form of virtualization (it shares Kernel with the host) than virtual machines because it does not contain virtual hardware as VMs do.

A container encapsulates all the software dependencies and configurations that a program needs, creating a closed environment for the program to function properly. As a result, we gain portability, which is the main advantage of Docker. This greatly simplified deployments and started to popularize the culture of microservices, encapsulating all kinds of programs in these containers to simplify their management.
The problem is that when this was adopted by the industry, manual container management became inefficient. For example, it’s impossible to think that Google only manages about 10 containers, it probably manages millions, and simplifying deployment was great, but with it, a new need was created. Software that would manage all containers and minimize manual optimization and review tasks such as scalability improvements, check for failures, or take into account the communication between these containers, which are isolated by default.
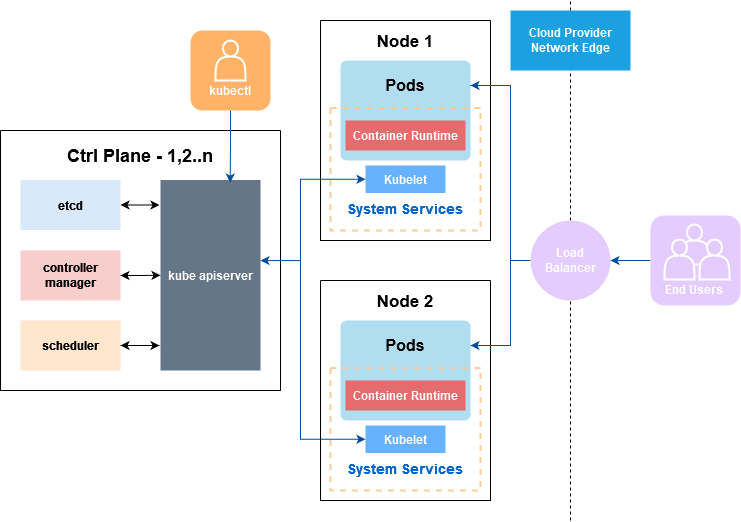
All these aspects encouraged, in 2015, the creation, by Google, of Kubernetes, a container orchestrator that solved and simplified all those details. This orchestrator works by separating the functional components, on the one hand, the Control Plane and on the other, the Worker nodes.
The Control Plane is in charge of the operation of the cluster, it has four fundamental parts:
- Etcd: stores configuration (etcd).
- Controller Manager: Contains all the controllers, for example, the one for the nodes, in charge of monitoring the workers and knowing their status, among others.
- Scheduler: It is in charge of deciding which containers go to each node.
- Kube-apiserver: The Api provided by Control Plane to manage all these details.
The Workers nodes, which are in charge of executing the workloads, are divided into three parts. We can have n workers and the functionality of the Control Plane is to manage them and divide their workloads:
- Kubelet: It is an agent that runs on each node and ensures that the containers are deployed in instances called “pods”. One of the main functionalities is the supervision of the health and correct execution of these containers.
- Kube-proxy: It is responsible for networking within the Kubernetes network. Redirects requests, controls permissions and enforces relevant policies to meet the desired communication.
- Container runtime: It is the container execution engine we use for virtualization, typically containerd (Docker).
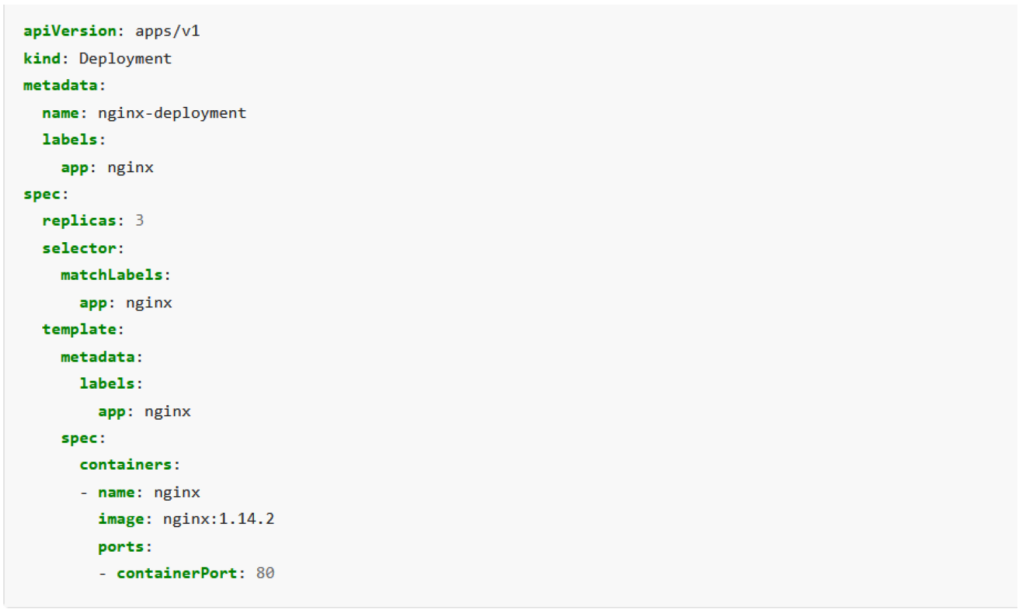
Applications to run on Kubernetes have to be described by a file called manifest. There is a type of resources called Deployments that are in charge of defining our application.
Beyond this small base, networking by default is isolated, just as in Docker, by default only internal content can be accessed, the same applies to Kubernetes. Nonetheless, there are mechanisms that indicate to the proxy that it has to allow a certain communication flow. This is why there are components called Services, whose main function is to expose an application so that it can be accessed from outside the cluster (the case of the Load Balancer in the image above).
The main advantages of Kubernetes are the flexibility, resiliency and high availability it offers. For example, when it detects that a container has failed, it automatically redeploys it. When it sees that a Worker node is heavily loaded in terms of resources, it tries (whenever possible) to balance the load between the other nodes in the cluster, which is possible thanks to the portability of containers, since it is very easy to move a container between two nodes.
But one of the most important features of Kubernetes, considering the rise of Cloud Computing, is the high scalability it offers. We have components within Kubernetes that are able to monitor the load that a container is having and when exceeding certain resource limits set by the administrator, it scales the application generating a copy of the container and dividing the load between the resulting containers. In this way, it lightens the load on the first container and distributes the requests between the two containers.
This casuistry has become very interesting in the Cloud environment, since a system can eventually become as scalable as we want it to be. If an application has a load spike, Kubernetes can autonomously distribute the load across the cluster to verify the correct operation of the application. But in the event that all nodes in the cluster are experiencing a load that prevents the normal operation of the application, there are other tools that allow to automatically provision nodes to the cluster with machines from Cloud providers to solve this peak without downtimes.
In conclusion, nowadays Kubernetes has become not a great advantage in the infrastructure, but a necessity due to all the advantages it presents, which solve everyday problems and, as we have seen in this article, greatly lighten the workload of system administrators and in large enterprise environments where this complexity can become gigantic if you do not have a proper management mechanism like this one.