
La integració de dades és una àrea de recerca amb multitud d’aplicacions com ara en el món empresarial (p.e., per donar accés a sistemes legacy o a serveis externs), ciència (p.e., per combinar informació dels centenars de bases de dades biomèdiques existents), o bé a la Web (p.e., per tal de construir una plataforma d’anàlisi i comparació de preus de productes). Tots aquests exemples requereixen el desenvolupament d’un sistema capaç de modelar múltiples fonts de dades autònomes, i proporcionar una interfície de consultes uniforme sobre aquestes. Una solució clàssica a aquest problema és l’ús d’una base de dades federada com es mostra en la següent figura. Aquest sistema està compost per diferents mòduls encarregats d’homogeneïtzar, a través dels wrappers, les dades provinents d’una varietat de bases de dades. L’usuari pot executar consultes (p.e., usant SQL) sobre un esquema global i el sistema, a través dels mediators, s’encarrega automàticament de reescriure aquesta en un conjunt de subconsultes sobre cada una de les bases de dades, i composar els resultats parcials per donar-ne una visió integrada. Això dóna a l’usuari la percepció de què interactua amb una única base de dades i no una federació d’aquestes.
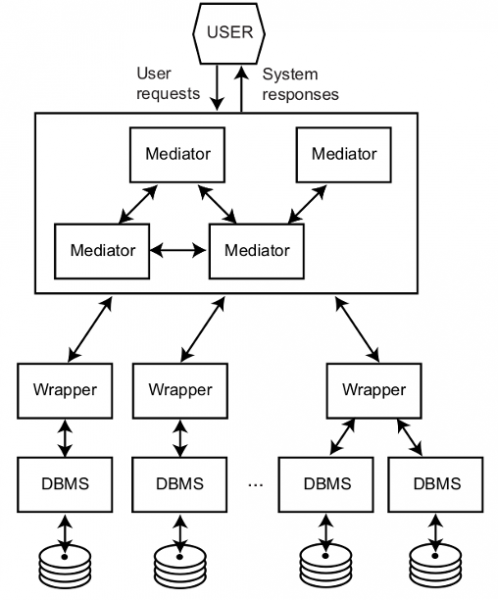
Arquitectura Mediator/Wrapper (font, Principles of Distributed Database Systems)
A la pràctica pocs sistemes existeixen oferint aquestes funcionalitats, i majoritàriament estan centrats en la mediació de bases de dades relacionals. Malgrat això, avui en dia les organitzacions volen analitzar i enriquir les seves dades amb fonts de dades externes com ara aquestes que es poden trobar en portals de dades obertes o descarregables mitjançant APIs. La meva tesi doctoral, la qual recentment ha rebut el premi SISTEDES, parteix d’aquesta premissa i segueix una línia de recerca en el desenvolupament de sistemes d’integració de dades flexibles i eficients per tal de gestionar els reptes presentats quan treballem amb grans volums de dades i amb una gran varietat (Big Data).
En aquest post resumiré dues de les contribucions resultants d’un treball dut a terme en cotutela entre UPC i ULB de 2015 a 2019, i dirigit pels professors Alberto Abelló (UPC), Oscar Romero (UPC) i Stijn Vansummeren (ULB).
Bolster: una arquitectura software de referencia per a sistemes Big Data
Els fonaments per poder realitzar integració de dades són les metadades. Aquestes són les dades que descriuen el sistema d’integració (l’esquema global, l’esquema de les fonts, les relacions entre aquests, etc.). Els sistemes gestors de bases de dades relacionals incorporen la gestió de metadades, però això no és cert pel cas dels sistemes moderns de processament de dades massives. Aquests es caracteritzen per estar compostos de components independents (aquells coneguts normalment com a NOSQL, p.e., Hadoop, Spark, o MongoDB), que generalment funcionen de forma aïllada. La definició d’una arquitectura de sistema que inclogui aquests components, i els processos d’extracció, transformació i càrrega de dades és una tasca de responsabilitat dels administradors del sistema.
Per tal de facilitar a les organitzacions la tasca d’adoptar aquest tipus de tecnologies vam introduir Bolster (veure la figura següent), una arquitectura software de referència (SRA) per a sistemes Big Data. Una SRA es pot considerar com un plànol on es descriuen un conjunt de components software i les seves relacions. Cadascun d’aquests components es pot instanciar amb una eina de l’ecosistema Apache, o Amazon Web Services (AWS). Una de les contribucions de Bolster és la incorporació d’una capa semàntica, la qual té l’objectiu d’emmagatzemar i servir les metadades necessàries per automatitzar la comunicació de dades entre components.
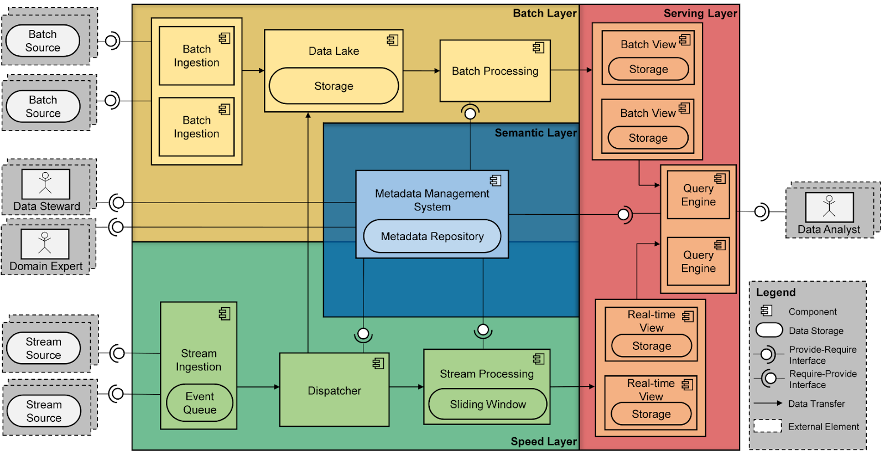
Bolster s’ha posat en pràctica en múltiples projectes en col·laboració amb la indústria. L’exemple més rellevant és el projecte Las Moiras de AdQore, el qual va permetre automatitzar el protocol de governança de dades d’AdQuiver.
ODIN: extracció, integració i consulta automàtica de fonts de dades heterogènies
Un cop disposem d’una arquitectura desplegada, és necessari generar les metadades necessàries per a realitzar la integració de dades (aquella informació que es guarda a la capa semàntica). En aquesta tesi ens vam centrar en entorns amb centenars de fonts de dades i servint dades en formats diferents (p.e., JSON, CSV, XML, etc). En aquestes situacions el manteniment manual de les metadades és inviable i s’ha de realitzar de forma automàtica.
El projecte ODIN (On-Demand Data Integration) té com a objectiu automatitzar el procés d’extracció i integració de metadades per poder realitzar consultes federades. ODIN representa totes les metadades com a graf per tal de facilitar la seva interoperabilitat (p.e., una consulta es representa com a un subgraf d’un graf). El cicle de vida d’ODIN (veure la següent figura) està dividit en tres fases:
- Extracció de l’esquema de les fonts de dades a graf, on es generen els source graphs que modelen l’estructura física de les fonts.
- Integració de diferents fonts automàtica, a partir d’alineaments descoberts automàticament amb el suport d’un expert en el domini.
- Execució de consultes federades, on es tradueix una consulta sobre el graf global a un conjunt de consultes sobre les fonts i els resultats parcials es composen (usant operacions d’unió i join).
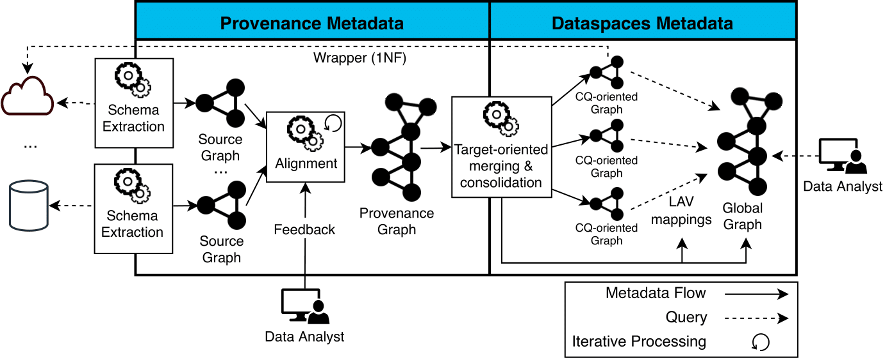
ODIN és un projecte que va més enllà de la meva tesi doctoral, i on hi ha moltes oportunitats de recerca. Un exemple és el projecte An Automatic Data Discovery Approach to Enhance Barcelona’s Data Ecosystem, el qual es centra en la fase de descobrir relacions (alineaments) entre fonts de dades enfocat en l’ecosistema de dades de la ciutat de Barcelona, o bé el sistema NextiaJD liderat per l’estudiant de doctorat Javier Flores.
Més informació
La tesi completa està disponible a tdx.cat. En els següents articles podreu trobar detalls sobre els temes explicats en aquest post: