
És bastant normal tenir alta disponibilitat per serveis que es consideren crítics dins d’una organització. En aquest cas concret, posem que volem implementar l’alta disponibilitat pels sistemes de control perimetral (firewalls) que tenim a una xarxa controlada per l’inLab.
El fet que un d’aquests sistemes de control fallés deixaria la xarxa aïllada. Per tant, és crític tenir el servei en alta redundància de manera que si un servidor falla, un altre assumeix el servei.
Introducció
És bastant normal tenir alta disponibilitat per serveis que es consideren crítics dins d’una organització. En aquest cas concret, posem que volem implementar l’alta disponibilitat pels sistemes de control perimetral (firewalls) que tenim a una xarxa controlada per l’inLab.
El fet que un d’aquests sistemes de control fallés deixaria la xarxa aïllada. Per tant, és crític tenir el servei en alta redundància de manera que si un servidor falla, un altre assumeix el servei.
El software que hem utilitzat per tenir alta disponibilitat es diu Pacemaker de Cluster Labs.
Està disponible a la majoria de distribucions directament a la mateixa paqueteria, tot i que també ens podem descarregar el codi i compilar-lo nosaltres per la nostra plataforma.
Conceptes
En el nostre cas tenim dos servidors que executen serveis crítics per tant cal configurar-los amb el software d’alta disponibilitat de manera que s’organitzin els serveis, es monitorin i si hi ha algun problema, es pugui recuperar el servei amb el menor temps de fallada possible.
Actiu/Actiu vs. Actiu/Passiu
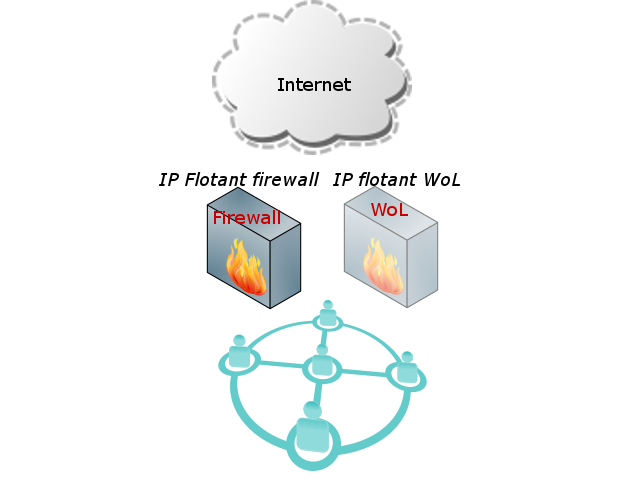
Els clústers de servidors en alta disponibilitat es poden organitzar de manera que totes dues màquines donin el servei o que una, l’activa, el doni i l’altre només entri a donar servei si la primera falla. La manera d’aprofitar millor els recursos seria fer que totes dues màquines executessin el servei però a vegades no es possible ja que hi ha serveis que tenen estat i només permetrien execució en una màquina. És el cas dels firewalls, ja que hi ha l’estat de les connexions que és complicat de sincronitzar entre dos servidors, per tant hem optat per utilitzar la configuració actiu-passiu, una màquina assumeix el rol de firewall primari i l’altre es queda sense el servei monitorant si la primera falla. Per tal que la màquina que està passiva no estigui sense fer res, hi ha un altre servei que ens van bé que s’executi en alta disponibilitat, que és el proxy de Wake On Lan i amb el Pacemaker podem fer que s’executi preferentment al servidor que no té el firewall.
D’aquesta manera aconseguim que les dues màquines estiguin ocupades i aprofitem una mica millor els recursos.
Recursos
Tenim dos servidors que segons el Pacemaker reben el nom de nodes, el servei de firewall que necessita un software (en aquest cas netfilter.org) amb una política, unes IPs “flotants” i el servei de Wake On Lan (a partir d’ara WoL).
Les IPs flotants són adreces que no estan assignades a una màquina sinó que estan connectades al servei i el servidor que executi el servei és el que ha de tenir aquella adreça. Per tant, reben el nom de flotants perquè poden anar d’una màquina a un altre depenent d’on estigui el servei.
Totes dues màquines han de ser capaces d’executar les regles de firewall i el servei de WoL. De manera que totes dues tenen el netfilter, el software de WoL i les regles/configuracions sincronitzades. Això ho aconseguim amb la comanda rsync executada cada cert temps des del cron.
Per tant identifiquem com a recursos les IPs flotants més el software a executar per oferir el firewall i el WoL.
Prioritats
Amb les prioritats podem definir que un servei s’executi a una màquina en concret quan les dues estan en marxa, el que es fa és definir major prioritat a un node per un determinat servei o conjunt de serveis. Això ens va molt bé per definir les alarmes i documentació de les màquines, ja que definim una com primària per un determinat servei i l’altre com secundària.
Quòrum
Un clúster té quòrum quan més de la meitat dels nodes del clúster estan actius i han pogut comunicar-se satisfactòriament. Així si tenim un clúster de 5 nodes, la xarxa té un problema i 3 nodes queden aïllats dels altres 2, el miniclúster de 3 nodes seguirà servint els serveis mentre els altres 2 no ho faran, ja que no arriben al quòrum mínim.
En el nostre cas el tema del quòrum es tracta diferent, ja que només tenim dos servidors, per tant el funcionament és diferent i el clúster podria arribar a funcionar només amb un servidor actiu i l’altre caigut.
Monitoratge i Fencing
Els dos nodes del clúster estan connectats en una xarxa privada de manera que la comunicació és el més directe possible i es van monitorant per veure que tot funciona correctament (tenen quòrum), quan hi ha algun problema a la comunicació o un node detecta que l’altre està malfuncionant (un dels serveis crítics no està en marxa, no respon suficientment ràpid, hi ha problemes de disc, etc.) ha de prendre la decisió de convertir-se en node primari i executar ell els serveis crítics.
Es podria donar el cas que tots els servidors detectessin que hi ha algun problema i els dos alhora decidissin que l’altre està malfuncionant assumint tant la IP com el servei a la vegada, el que provocaria un caos a la xarxa, aquesta situació es coneix com split-brain. Per evitar això tenim el fencing.
El mecanisme de fencing que fem servir es diu STONITH que significa Shoot The Other Node In The Head , que és una manera molt clara d’explicar que un servidor “dispara una bala al cap” de l’altre node de manera que aconsegueix parar-lo per a què no es doni el problema de què tots dos assumeixen el servei (split-brain). Un cop parat l’altre servidor pot assumir tranquil·lament tots els serveis i recursos del clúster.
Recuperació
Un cop s’ha produït un problema, s’ha executat el fencing i tenim el servei restablert tot i que en un clúster degradat (ja que hi hauria un servidor que s’ha hagut de sacrificar) cal una intervenció tècnica per tornar a recuperar la situació inicial. És a dir, posar en marxa el servidor sacrificat, veure quin problema tenia, solucionar-ho i tornar a posar el clúster en marxa.
De manera automàtica i gràcies a les prioritats un cop el clúster està en marxa es torna a establir la configuració inicial, amb un servidor primari tal com havíem definit i l’altre com a secundari, en aquest cas un tindria la IP i serveis del firewall, mentre l’altre tindria la IP i servei de WoL.
Hands On
Fem una configuració bàsica del fitxer /etc/corosync/corosync.conf, on posem els nodes del clúster, la xarxa, protocol per la comunicació, on es fa el logging. El corosync seria el daemon que forma part del software d’alta disponibilitat que s’encarrega de la comunicació entre nodes.
miserver /root# cat /etc/corosync/corosync.conf
totem {
version: 2
crypto_cipher: none
crypto_hash: none
clear_node_high_bit: yes
interface {
ringnumber: 0
bindnetaddr: Xarxa IP interna
mcastport: Port
ttl: 1
}
transport: udpu --> Significa que utilitzem UDP per la comunicació enlloc de multicast (al tenir només dos
servidors ja ens va bé)
}
logging { --> Configurem els logs cap al SYSLOG
fileline: off
to_syslog: yes
debug: off
timestamp: on
logger_subsys {
subsys: QUORUM
debug: off
}
}
nodelist { --> La llista de nodes del clúster i posem les IPs privades
node {
ring0_addr: 192.168.10.1
nodeid: 1
}
node {
ring0_addr: 192.168.10.2
nodeid: 2
}
}
quorum { --> Al ser un clúster de dos nodes es necessari definir l'opció two_node
provider: corosync_votequorum
two_node: 1
no-quorum-policy: ignore
stonith-action: poweroff --> si hi ha un problema apagem el servidor que està donant el problema
}
Un cop tenim la mateixa configuració als dos servidors i hem posat en marxa el daemon de corosync podem utilitzar l’eina de línia de comandes crm per configurar recursos, prioritats, fencing en un dels nodes, ja que amb el corosync la configuració s’aplicarà a tots els nodes del clúster.
Per a què el clúster estigui funcionant correctament cal que els nodes estableixin un quòrum, si fem crm status veure’m que ens diu “partition with quorum”.
miserver:/root # systemctl start corosync; systemctl start pacemaker miserver:/root # crm status Stack: corosync Current DC: miserver (2) - partition with quorum 2 Nodes configured 0 Resources configured Online: [ node1 node2 ]
Configurem una IP flotant i un servei: En aquest cas configuraria el que és el WoL però pel firewall seria el mateix. El que posa lsb:nom_servei vol dir que el servidor té definit un servei que es pot fer start/stop que es diu nom_servei. Si no està aquest servei, la configuració de clúster et dóna un error.
miserver /root# crm configure primitive ipWOL IPaddr2 params ip=10.10.10.254 cidr_netmask=24 op monitor interval=30s primitive wol_relay lsb:wol_relay op monitor interval=15s group WOL ipWOL wol_relay location WOL1 WOL 100: NODE1 location WOL2 WOL 50: NODE2 commit
STONITH: Es configura per NODE1 i també per NODE2
miserver /root#crm configure primitive shootNODE1 stonith:external/ipmi params hostname="node1fencing" ipaddr="xxxx" userid="fence" passwd="XXX" interface="lanplus" stonith-timeout="30s" op monitor interval=120s miserver /root# crm configure location shootNODE1LOC shootNODE1 -inf: NODE1
Fem el mateix pel node2
Finalment amb tota la configuració feta i havent resolt problemes que ens puguem haver trobat el crm status hauria de donar quelcom així:
NODE1:/root # crm status Stack: corosync Current DC: NODE1 (2) - partition with quorum 2 Nodes configured 7 Resources configured Online: [ NODE1 NODE2 ] shootNODE2 (stonith:extNODE2/ipmi): Started NODE1 Resource Group: WOL ipWOL (ocf::heartbeat:IPaddr2): Started NODE2 wol_relay (lsb:wol_relay): Started NODE2 Resource Group: FW gwip (ocf::heartbeat:IPaddr2): Started NODE1 gw4ip (ocf::heartbeat:IPaddr2): Started NODE1 firewall (lsb:firewall_cluster): Started NODE1
Conclusió
Abans d’utilitzar Pacemaker utilitzàvem un software que es deia Heartbeat (en realitat predecessor de Pacemaker).
Era molt més senzill d’instal·lar i configurar però li faltaven moltes més coses que han millorat a Pacemaker, el tema d’ordre i prioritats per exemple.
També és millor la possibilitat de configuració amb l’eina crm que fa que es repliqui la configuració a tots els nodes del clúster.
En resum, al principi sembla una tasca més complexa utilitzar Pacemaker però li vas veient els beneficis i un cop et fas amb la sintaxi és un software molt potent per a gestionar l’alta disponibilitat de serveis a linux.