Es bastante normal tener alta disponibilidad para servicios que se consideran críticos dentro de una organización. En este caso concreto, pongamos que queremos implementar la alta disponibilidad para los sistemas de control perimetral (firewalls) que tenemos en una red controlada por inLab.
El hecho de que uno de estos sistemas de control fallase dejaría la red aislada. Por lo tanto, es crítico tener el servicio en alta redundancia de forma que si un servidor falla, otro asume el servicio.
Introducción
Es bastante normal tener alta disponibilidad para servicios que se consideran críticos dentro de una organización. En este caso concreto, pongamos que queremos implementar la alta disponibilidad para los sistemas de control perimetral (firewalls) que tenemos en una red controlada por inLab.
El hecho de que uno de estos sistemas de control fallase dejaría la red aislada. Por lo tanto, es crítico tener el servicio en alta redundancia de forma que si un servidor falla, otro asume el servicio.
El software que hemos usado para tener alta disponibilidad se llama Pacemaker de Cluster Labs.
Está disponible en la mayoría de distribuciones, directamente en la misma paquetería, pero también podemos descargarnos el código y compilarlo nosotros para nuestra plataforma.
Conceptos
En nuestro caso tenemos dos servidores que ejecutan servicios críticos por lo tanto hay que configurarlos con el software de alta disponibilidad de forma que se organicen los servicios, se monitoricen y si hay algún problema, se pueda recuperar el servicio con el menor tiempo de fallo posible.
Activo/Activo vs. Activo/Pasivo
Los clústeres de servidores en alta disponibilidad se pueden organizar de forma que las dos máquinas den el servicio o que una, la activa, lo dé y la otra sólo entre a dar servicio si la primera falla. La manera de aprovechar mejor los recursos seria hacer que las dos máquinas ejecutasen el servicio, pero a veces no es posible ya que hay servicios que tienen estado y sólo permitirían ejecución en una máquina. Es el caso de los firewalls, ya que hay el estado de las conexiones que es complicado sincronizar entre dos servidores, por lo tanto hemos optado por usar la configuración activo-pasivo, una máquina asume el rol de firewall primario y la otra se queda sin el servicio monitorizando si la primera falla. Con tal de que la máquina que está pasiva no esté sin hacer nada, hay otro servicio que nos va bien que se ejecute en alta disponibilidad, que es el proxy de Wake On Lan y con el Pacemaker podemos hacer que se ejecute preferentemente en el servidor que no tiene el firewall.
De esta forma conseguimos que las dos máquinas estén ocupadas y aprovechamos un poco mejor los recursos.
Recursos
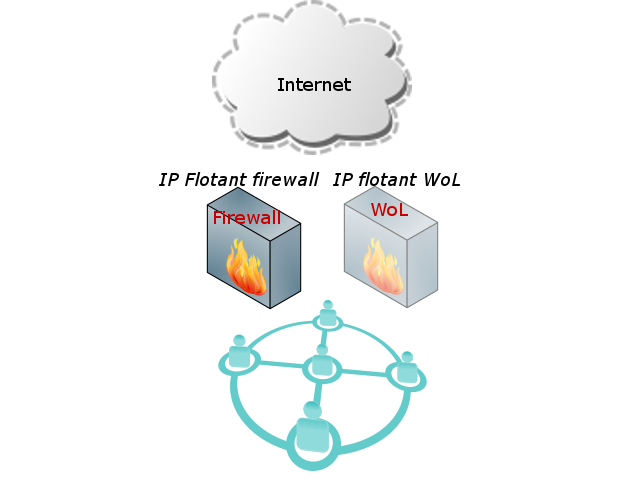
Tenemos dos servidores que, según el Pacemaker, reciben el nombre de nodos, el servicio de firewall que necesita un software (en este caso netfilter.org) con una política, unas IPs “flotantes” y el servicio de Wake On Lan (a partir de ahora WoL).
Las IPs flotantes son direcciones que no están asignadas a una máquina sino que están conectadas al servicio y el servidor que ejecute el servicio es el que ha de tener esa dirección. Por lo tanto, reciben el nombre de flotantes porque pueden ir de una máquina a otra dependiendo de donde esté el servicio.
Las dos máquinas tienen que ser capaces de ejecutar las normas del firewall y el servicio de WoL. De forma que las dos tienen el netfilter, el software de WoL y las normas/configuraciones. Esto lo conseguimos con el comando rsync ejecutado cada cierto tiempo desde el cron.
Por lo tanto, identificamos como recursos las IPs flotantes más el software a ejecutar para ofrecer el firewall y el WoL.
Prioridades
Con las prioridades podemos definir que un servicio se ejecute en una máquina en concreto cuando las dos están en marcha, lo que hace es definir mayor prioridad a un nodo para un determinado servicio o conjunto de servicios. Esto nos va muy bien para definir las alarmas y documentación de las máquinas ya que definimos una como primaria para un determinado servicio y la otra como secundaria.
Cuórum
Un clúster tiene cuórum cuando más de la mitad de los nodos del clúster están activos y han podido comunicarse satisfactoriamente. Así, si tenemos un clúster de 5 nodos, la red tiene un problema y 3 nodos quedan aislados de los otros 2, el miniclúster de 3 nodos seguirá sirviendo los servicios mientras que los otros 2 no lo harán, ya que no llegan al cuórum mínimo.
En nuestro caso, el tema del cuórum se trata diferente, ya que sólo tenemos dos servidores, por lo tanto el funcionamiento es distinto y el clúster podría llegar a funcionar con sólo un servidor activo y el otro caído.
Monitorización y Fencing
Los dos nodos del clúster están conectados a una red privada de forma que la comunicación es lo más directa posible y se van monitorizando para ver que todo funciona correctamente (tienen cuórum), cuando hay algún problema en la comunicación o un nodo detecta que el otro está malfuncionando (uno de los servicios críticos no está en marcha, no responde suficientemente rápido, hay problemas de disco, etc.) tiene que tomar la decisión de convertirse en nodo primario y ejecutar él los servicios críticos.
Se podría dar el caso que todos los servidores detectaran que hay algún problema y los dos decidieran a la vez que el otro está malfuncionando, asumiendo tanto la IP como el servicio a la vez, lo que provocaría un caos en la red, esta situación se conoce como split-brain. Para evitar esto tenemos el fencing.
El mecanismo de fencing que usamos se llama STONITH que significa “Shoot The Other Node In The Head”, que es una forma muy clara de explicar que un servidor “dispara una bala a la cabeza” del otro nodo, de forma que consigue pararlo para que no se dé el problema de que los dos asuman el servicio (split-brain). Una vez parado el otro servidor puede asumir tranquilamente todos los servicios y recursos del clúster.
Recuperación
Una vez se ha producido un problema, se ha ejecutado el fencing y tenemos el servicio reestablecido a pesar de que en un clúster degradado (ya que habría un servidor que se ha tenido que sacrificar) hace falta una intervención técnica para volver a recuperar la situación inicial. Es decir, poner en marcha el servidor sacrificado, ver qué problema tenía, solucionarlo y volver a poner el clúster en marcha.
De forma automática y gracias a las prioridades, una vez el clúster está en marcha se vuelve a establecer la configuración inicial, con un servidor primario tal como habíamos definido y el otro como secundario, en este caso uno tendría IP y servicios del firewall, mientras que el otro tendría la IP y servicio de WoL.
Hands On
Hacemos una configuración básica del fichero /etc/corosync/corosync.conf, donde ponemos los nodos del clúster, la red, protocolo para la comunicación, donde se hace el logging. El corosync sería el daemon que forma parte del software de alta disponibilidad que se encarga de la comunicación entre nodos.
miserver /root# cat /etc/corosync/corosync.conf
totem {
version: 2
crypto_cipher: none
crypto_hash: none
clear_node_high_bit: yes
interface {
ringnumber: 0
bindnetaddr: Red IP interna
mcastport: Puerto
ttl: 1
}
transport: udpu --> Significa que usamos UDP para la comunicación en lugar de multicast (al tener sólo dos
servidores ya nos va bien)
}
logging { --> Configuramos los logs hacia el SYSLOG
fileline: off
to_syslog: yes
debug: off
timestamp: on
logger_subsys {
subsys: QUORUM
debug: off
}
}
nodelist { --> La lista de nodos del clúster y ponemos las IPs privadas
node {
ring0_addr: 192.168.10.1
nodeid: 1
}
node {
ring0_addr: 192.168.10.2
nodeid: 2
}
}
quorum { --> Al ser un clúster de dos nodos es necesario definir la opción two_node
provider: corosync_votequorum
two_node: 1
no-quorum-policy: ignore
stonith-action: poweroff --> si hay un problema apagamos el servidor que está dando el problema
}
Una vez tenemos la misma configuración en los dos servidores y hemos puesto en marcha el daemon de corosync, podemos usar la herramienta de línea de comandos crm para configurar recursos, prioridades, fencing en uno de los nodos, ya que con el corosync la configuración se aplicará a todos los nodos del clúster.
Para que el clúster esté funcionando correctamente hace falta que los nodos establezcan un cuórum, si hacemos crm status veremos que nos dice “partition with quorum”.
miserver:/root # systemctl start corosync; systemctl start pacemaker miserver:/root # crm status Stack: corosync Current DC: miserver (2) - partition with quorum 2 Nodes configured 0 Resources configured Online: [ node1 node2 ]
Configuramos una IP flotante y un servicio: En este caso configuraría el que es el WoL pero para el firewall sería lo mismo. Lo que pone lsb:nombre_servicio quiere decir que el servidor tiene definido un servicio que se puede hacer start/stop que se llama nombre_servicio. Si no está este servicio, la configuración del clúster da un error.
miserver /root# crm configure primitive ipWOL IPaddr2 params ip=10.10.10.254 cidr_netmask=24 op monitor interval=30s primitive wol_relay lsb:wol_relay op monitor interval=15s group WOL ipWOL wol_relay location WOL1 WOL 100: NODE1 location WOL2 WOL 50: NODE2 commit
STONITH: Se configura para NODE1 y también para NODE2
miserver /root#crm configure primitive shootNODE1 stonith:external/ipmi params hostname="node1fencing" ipaddr="xxxx" userid="fence" passwd="XXX" interface="lanplus" stonith-timeout="30s" op monitor interval=120s miserver /root# crm configure location shootNODE1LOC shootNODE1 -inf: NODE1
Hacemos lo mismo para NODE2
Finalmente, con toda la configuración hecha y habiendo resuelto problemas que nos hayamos encontrado, el crm status tendría que dar algo así:
NODE1:/root # crm status Stack: corosync Current DC: NODE1 (2) - partition with quorum 2 Nodes configured 7 Resources configured Online: [ NODE1 NODE2 ] shootNODE2 (stonith:extNODE2/ipmi): Started NODE1 Resource Group: WOL ipWOL (ocf::heartbeat:IPaddr2): Started NODE2 wol_relay (lsb:wol_relay): Started NODE2 Resource Group: FW gwip (ocf::heartbeat:IPaddr2): Started NODE1 gw4ip (ocf::heartbeat:IPaddr2): Started NODE1 firewall (lsb:firewall_cluster): Started NODE1
Conclusión
Antes de usar Pacemaker usábamos un software que se llamaba Heartbeat (en realidad predecesor de Pacemaker).
Era mucho más sencillo de instalar y configurar pero faltaban muchas cosas que han mejorado en Pacemaker, el tema de orden y prioridades por ejemplo.
También es mejor la posibilidad de configuración con la herramienta crm que hace que se replique la configuración en todos los nodos del clúster.
En resumen, al principio usar Pacemaker parece una tarea más compleja, pero le vas viendo los beneficios y una vez te haces con la sintaxis es un software muy potente para gestionar la alta disponibilidad de servicios en Linux.