Desde la creación de Internet y cada vez más, se ha contado con datos generados por infinidad de aplicaciones y que tenemos a nuestro alcance esperando a ser usados. Antaño, tener y consumir todo este ingente material se podía volver una tarea prácticamente imposible o inviable tanto económica como tecnológicamente.
Introducción
Desde la creación de Internet y cada vez más, se ha contado con datos generados por infinidad de aplicaciones y que tenemos a nuestro alcance esperando a ser usados. Antaño, tener y consumir todo este ingente material se podía volver una tarea prácticamente imposible o inviable tanto económica como tecnológicamente. Esto limitaba el uso de la información a aquella que era más relevante y punto. Vamos a ver en que herramientas podemos iniciarnos para solventar este handicap y sacar el máximo valor a nuestros datos. Herramientas open-source y que cualquiera tiene a su disposición. El ecosistema Hadoop.
Hardware
 Hoy en día tenemos a nuestro alcance el poder consumir esta información sin necesidad de contar con un carísimo supercomputador en nuestro trastero. Podemos llegar a hacer pruebas con sistemas de 8-16GB de RAM y unos cuantos GB de disco duro. En un entorno de producción se usa «comodity hardware«, es decir, máquinas que no necesitan tener un alto grado de fiabilidad y sofisticación (sistemas RAID, discos duros enterprise, componentes redundantes, etc). Máquinas de este tipo son mucho más baratas y si se rompen, ponemos otras y ya está. El peso de la fiabilidad recae sobre el software. Tendremos, esto sí, que dimensionar las características según los requerimientos de nuestro escenario. Una configuración típica de un nodo de un entorno productivo podría ser una máquina con 8-24 cores, 32-256GB de RAM y unos 8-12 discos HDD.
Hoy en día tenemos a nuestro alcance el poder consumir esta información sin necesidad de contar con un carísimo supercomputador en nuestro trastero. Podemos llegar a hacer pruebas con sistemas de 8-16GB de RAM y unos cuantos GB de disco duro. En un entorno de producción se usa «comodity hardware«, es decir, máquinas que no necesitan tener un alto grado de fiabilidad y sofisticación (sistemas RAID, discos duros enterprise, componentes redundantes, etc). Máquinas de este tipo son mucho más baratas y si se rompen, ponemos otras y ya está. El peso de la fiabilidad recae sobre el software. Tendremos, esto sí, que dimensionar las características según los requerimientos de nuestro escenario. Una configuración típica de un nodo de un entorno productivo podría ser una máquina con 8-24 cores, 32-256GB de RAM y unos 8-12 discos HDD.
Para introducirnos en el uso de este software, no es necesario tener un cluster de máquinas potentes, podremos ponernos a trastear con un ¿Cubieboard cluster :)?, unas simples VM’s en nuestro PC o con alguna VM como la Cloudera QuickStart VM con todo ya montado, que sirve justamente para aprender.
Motivación

Antes de nada, dejemos clara una cosa y no nos engañemos, Big Data es para tratar con grandes volúmenes de datos. Big Data aparece cuando decidimos dejar de quedarnos con lo que era más relevante y pasar a quedarnos con TODO. Toda información sirve en algún momento y nos puede permitir ver cosas que con solamente «lo importante» no podemos llegar a ver y que en muchas ocasiones nos puede aportar mucho valor.
Como decíamos, hoy en día se ha vuelto factible tener mucha información y ser capaz de consumirla, pero también hay que entender cuando tiene sentido usar herramientas Big Data y cuando no. Si tenemos un volumen alto de datos y tenemos que lidiar con gigas y gigas de datos (o alguna magnitud mayor) estará bien usar estas herramientas. De no ser así, también podemos hacer uso de todo esto, pero matar moscas a cañonazos quizás no es tan adecuado, aunque sea la moda.
La Base
Hablar de Big Data es hablar de Hadoop y todo lo que lo rodea. Vamos a ver qué es Hadoop. Hadoop se sustenta en la forma en la que almacena y accede a los datos. Hadoop está formado por HDFS y MapReduce. La combinación de estos dos permite que los datos estén replicados y distribuidos por N nodos beneficiando la capacidad de acceso a grandes volúmenes. Cuando queremos ejecutar alguna operación sobre estos datos distribuidos, Hadoop se encarga de procesar cada porción de los datos en el nodo que los contiene. De esta forma se aprovecha la localidad de tener los datos cerca de donde se van a procesar y permite escalar de forma casi lineal. Si queremos crecer en capacidad, añadimos más nodos y listo. Del almacenamiento se encarga HDFS y del procesamiento MapReduce.
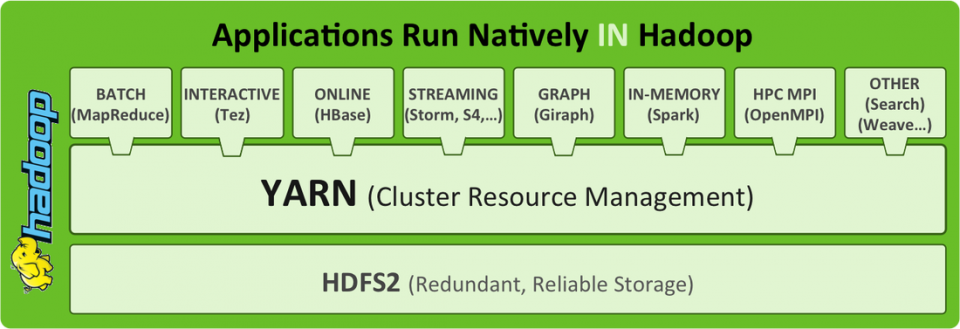
Complementos Básicos
Con HDFS y MapReduce tenemos la capacidad básica de almacenar datos en crudo y realizar procesos en paralelo abstrayéndonos de la complejidad de este tipo de computación. Ahora bien, podemos utilizar otras herramientas encima de Hadoop que nos potencian estas capacidades. Todo dependerá de nuestras necesidades. Estos son los dos más típicos:
HDFS
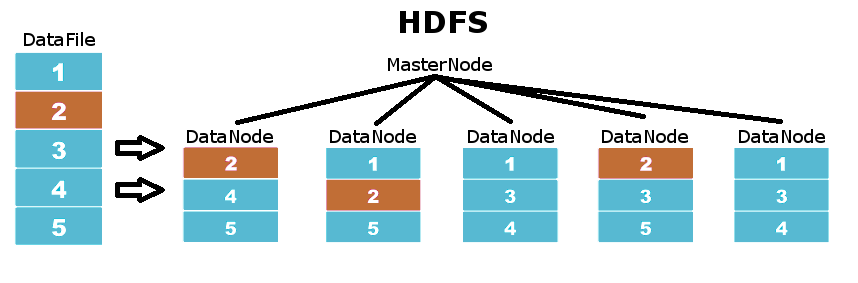
Es el filesystem en el que se basa Hadoop. Este sistema de ficheros se basa en una arquitectura master-slave donde los MasterNodes coordinan a los DataNodes, que son aquellos donde se guarda la información. Los datos en HDFS se distribuyen por los diferentes DataNodes en particiones del fichero original, asegurando que cada una de estas particiones está replicada en un nivel de replicación definido. Por tanto, no necesitamos disponer de sistemas con RAID, si un disco se estropea, HDFS automáticamente replica muy rápidamente todas las particiones que estaban en este disco en todo el resto de DataNodes.
YARN – MapReduce
YARN es la evolución de MapReduce para Hadoop 2.0. La función de YARN en Hadoop es la de proporcionar un entorno que gestione los recursos para realizar trabajos de computación. YARN se ocupa de distribuir el trabajo a hacer teniendo en cuenta donde están los datos a procesar, además de gestionar las propias ejecuciones de los programas. Con YARN podemos separar el sistema de ficheros del sistema de ejecución. Por tanto podemos usar HDFS sin pasar por YARN o bien usar este gestor de recursos para correr aplicaciones (Como es el caso de la mayoría de herramientas que trabajan en Hadoop).
HBase
![]()
![]() Se puede considerar «la base de datos» de Hadoop. Basado en BigTable de Google, proporciona la capacidad de crear tablas con millones de entradas y permite hacer accesos de lectura/escritura rápida y consistentemente. También es versionada y no-relacional, por lo que ofrece flexibilidad. Además es fácilmente conectable, ya sea a través de su API java o mediante web services. Podemos usar HBase para dar forma a nuestros datos.
Se puede considerar «la base de datos» de Hadoop. Basado en BigTable de Google, proporciona la capacidad de crear tablas con millones de entradas y permite hacer accesos de lectura/escritura rápida y consistentemente. También es versionada y no-relacional, por lo que ofrece flexibilidad. Además es fácilmente conectable, ya sea a través de su API java o mediante web services. Podemos usar HBase para dar forma a nuestros datos.
Hive
![]()
![]() Es una mezcla entre MapReduce y HBase. Permite estructurar los datos en tablas y vistas y nos permite realizar todo tipo de consultas usando su lenguaje de querying tipo SQL, el HiveQL. Para aquellos casos en los que no podamos obtener lo que queremos con HiveQL, podemos conectar Hive con nuestros propios mappers y reducers, ya que Hive es muy flexible en cuanto a conectividad y se le puede conectar cualquier cosa.
Es una mezcla entre MapReduce y HBase. Permite estructurar los datos en tablas y vistas y nos permite realizar todo tipo de consultas usando su lenguaje de querying tipo SQL, el HiveQL. Para aquellos casos en los que no podamos obtener lo que queremos con HiveQL, podemos conectar Hive con nuestros propios mappers y reducers, ya que Hive es muy flexible en cuanto a conectividad y se le puede conectar cualquier cosa.
Spark
![]()
![]() Es el rey que ha venido a conquistarlos a todos. Mientras que MapReduce realiza sus procesos sobre disco, Spark carga en memoria los datos y realiza operaciones entre datasets intermedios llamados RDDs. Esto hace que su rendimiento sea brutal. Además es bastante sencillo de utilizar y tiene soporte tanto para Scala como para Java y Python, contando con librerías para realizar procesamiento en micro-batch (STREAMING), machine learning (MLLIB), grafos (GRAPH) y SQL (SPARKSQL).
Es el rey que ha venido a conquistarlos a todos. Mientras que MapReduce realiza sus procesos sobre disco, Spark carga en memoria los datos y realiza operaciones entre datasets intermedios llamados RDDs. Esto hace que su rendimiento sea brutal. Además es bastante sencillo de utilizar y tiene soporte tanto para Scala como para Java y Python, contando con librerías para realizar procesamiento en micro-batch (STREAMING), machine learning (MLLIB), grafos (GRAPH) y SQL (SPARKSQL).
Otros Complementos
Además de la suite típica que hemos visto, hay muchos otros productos que funcionan junto con Hadoop y permiten nuevas funcionalidades. Según el tipo de aplicación usaremos unas u otras. También existen variantes de estas herramientas adaptadas a usos específicos, como SparkOnHBase, Spork, RHadoop y otros muchos más. Aquí tenéis una minúscula clasificación:
Data Engineering: Spark, Hive, Pig
Data Discovery & Analytics: Spark, Impala, Solr
Data Integration & Storage: HBase, Kudu, HDFS
Unified Data Services: Yarn, Sentry, Hue, Oozie
Data Ingestion: Sqoop, Flume, Kafka
Hands on
Hemos visto solo una pincelada de las herramientas que se usan para BigData. Dominarlas es cuestión de horas y de práctica. Para practicar, podéis hacer uso de la VM que anteriormente os comentaba para poner en practica alguno de los muchos cursos y tutoriales que se pueden encontrar on-line, como este curso gratuito, que te enseñarán desde hacer el clásico WordCount hasta realizar tareas de Analytics más complejas. También recomiendo encarecidamente echar mano de los clásicos libros O’Reilly específicos de cada tecnología.