
Des de la creació d’Internet i cada vegada més, s’ha comptat amb dades generades per infinitat d’aplicacions que tenim al nostre abast esperant a ser usades. Fins fa pocs anys, tenir i consumir tot aquest ingent material es podia tornar una tasca pràcticament impossible o inviable tant econòmica com tecnològicament.
Introducció
Des de la creació d’Internet i cada vegada més, s’ha comptat amb dades generades per infinitat d’aplicacions que tenim al nostre abast esperant a ser usades. Fins fa pocs anys, tenir i consumir tot aquest ingent material es podia tornar una tasca pràcticament impossible o inviable tant econòmica com tecnològicament. Això limitava l’ús de la informació a aquella que era més rellevant i punt. Anem a veure en quines eines podem iniciar-nos per solucionar aquest handicap i treure el màxim valor a les nostres dades. Eines open-source i que qualsevol té a la seva disposició. L’ecosistema Hadoop.
Maquinari
 Avui en dia tenim al nostre abast el fet de poder consumir aquesta informació sense necessitat de comptar amb un caríssim supercomputador. Podem arribar a fer proves amb sistemes d’uns 8-16GB de RAM i uns quants GB de disc dur. En un entorn de producció es fa servir “comodity hardware“, és a dir, màquines que no necessiten tenir un alt grau de fiabilitat i sofisticació (sistemes RAID, discs durs enterprise, components redundants, etc). Màquines d’aquest tipus són molt més barates i si es trenquen, en posem d’altres i ja està. El pes de la fiabilitat recau sobre el software. Haurem, això si, de dimensionar les característiques segons els requeriments del nostre escenari. Una configuració típica d’un node d’un entorn productiu podria ser una màquina amb 8-24cores, 32-256GB de ram i uns 8-12 discos HDD.
Avui en dia tenim al nostre abast el fet de poder consumir aquesta informació sense necessitat de comptar amb un caríssim supercomputador. Podem arribar a fer proves amb sistemes d’uns 8-16GB de RAM i uns quants GB de disc dur. En un entorn de producció es fa servir “comodity hardware“, és a dir, màquines que no necessiten tenir un alt grau de fiabilitat i sofisticació (sistemes RAID, discs durs enterprise, components redundants, etc). Màquines d’aquest tipus són molt més barates i si es trenquen, en posem d’altres i ja està. El pes de la fiabilitat recau sobre el software. Haurem, això si, de dimensionar les característiques segons els requeriments del nostre escenari. Una configuració típica d’un node d’un entorn productiu podria ser una màquina amb 8-24cores, 32-256GB de ram i uns 8-12 discos HDD.
Per introduir-nos en l’ús d’aquest software no cal tenir un cluster de màquines potents, podrem posar-nos a trastejar amb un ¿Cubieboard cluster 🙂 ?, unes simples VM ‘s en el nostre PC o amb alguna VM com la la Cloudera QuickStart VM amb tot ja muntat, que serveix justament per aprendre.
Motivació
 Abans de res, deixem clara una cosa i no ens enganyem, Big Data és per tractar amb grans volums de dades. Big Data apareix quan vam decidir deixar de quedar-nos amb el que era més rellevant i passar a quedar-nos amb TOT. Tota informació serveix en algun moment i ens pot permetre veure coses que amb només “el que és important” no podem arribar a veure i que en moltes ocasions ens pot aportar molt valor.
Abans de res, deixem clara una cosa i no ens enganyem, Big Data és per tractar amb grans volums de dades. Big Data apareix quan vam decidir deixar de quedar-nos amb el que era més rellevant i passar a quedar-nos amb TOT. Tota informació serveix en algun moment i ens pot permetre veure coses que amb només “el que és important” no podem arribar a veure i que en moltes ocasions ens pot aportar molt valor.
Com dèiem, avui dia s’ha tornat factible tenir molta informació i ser capaç de consumir-la, però també cal entendre quan té sentit usar eines Big Data i quan no. Si tenim un volum alt de dades i hem de lluitar amb gigues i gigues de dades (o alguna magnitud major) estarà bé usar aquestes eines. Si no és així, també podem fer ús de tot això, però matar mosques a canonades potser no és tan adequat, encara que sigui la moda.
La Base
Parlar de Big Data és parlar de Hadoop i tot el que l’envolta. Anem a veure què és Hadoop. Hadoop es sustenta en la forma que emmagatzema i accedeix a les dades. Hadoop està format per HDFS i MapReduce. La combinació d’aquests dos permet que les dades estiguin replicades i distribuïdes per N màquines beneficiant la capacitat d’accés. Quan volem executar alguna operació sobre aquestes dades distribuïdes, Hadoop s’encarrega de processar cada porció de les dades en el node que les conté. D’aquesta manera s’aprofita la localitat de tenir les dades a prop d’on es processaran i permet escalar de forma gairebé lineal. Si volem créixer en capacitat, afegim més nodes i llest. De l’emmagatzematge s’encarrega HDFS i del processament MapReduce.
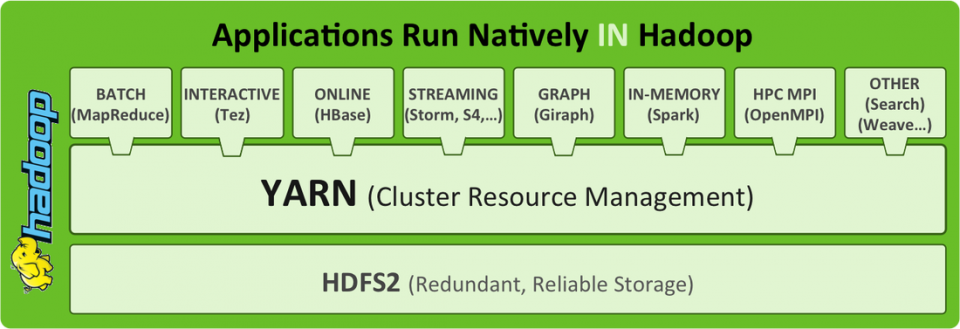
Complements Bàsics
Amb HDFS i MapReduce tenim la capacitat bàsica d’emmagatzemar dades en cru i realitzar processos en paral·lel abstraient-nos de la complexitat d’aquest tipus de computació. Ara bé, podem utilitzar per sobre de Hadoop altres eines que ens potencien aquestes capacitats. Tot dependrà de les nostres necessitats. Aquests són els dos més típics:
HDFS
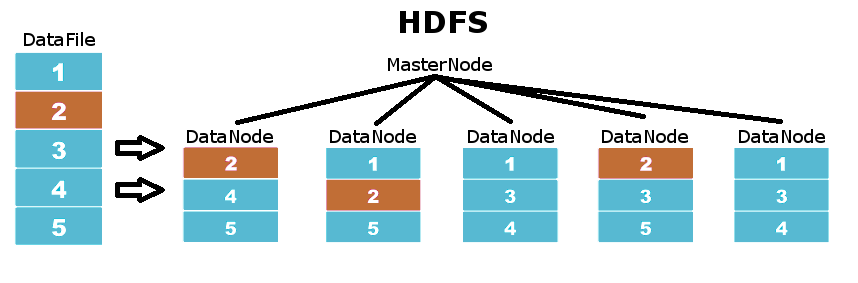
És el filesystem en el que es basa Hadoop. Aquest sistema de fitxers es basa en una arquitectura master-slave on els MasterNodes coordinen als DataNodes que són aquells on es guarda la informació. Les dades a HDFS es distribueixen pels diferents DataNodes en particions del fitxer original, assegurant que cadascuna d’aquestes particions està replicada en un nivell de replicació definit. Per tant, no necessitem disposar de sistemes amb RAID, si un disc s’espatlla, HDFS automàticament replica molt ràpidament totes les particions que estaven en aquest disc arreu de la resta de DataNodes.
YARN – MapReduce
YARN és l’evolució de MapReduce per a Hadoop 2.0. La funció de YARN en Hadoop és la de proporcionar un entorn que gestioni els recursos per a realitzar treballs de computació. YARN s’encarrega de distribuir la feina a fer tenint en compte on són les dades a processar, a més de gestionar les pròpies execucions dels programes. Amb YARN podem separar el sistema de fitxers del sistema d’execució. Per tant podrem fer servir HDFS sense passar per YARN o bé fer-nos servir d’aquest gestor de recursos per a córrer aplicacions (Com és el cas de la majoria de les eines que treballen en Hadoop).
HBase
![]()
![]() Es pot considerar “la base de dades” de Hadoop. Basat en BigTable de Google, proporciona la capacitat de crear taules amb milions d’entrades i permet fer accessos de lectura / escriptura ràpida i consistentment. També és versionada i no-relacional, de manera que ofereix flexibilitat. A més és fàcilment connectable, ja sigui a través de la seva API java o mitjançant web services. Podem fer servir HBase per donar forma a les nostres dades.
Es pot considerar “la base de dades” de Hadoop. Basat en BigTable de Google, proporciona la capacitat de crear taules amb milions d’entrades i permet fer accessos de lectura / escriptura ràpida i consistentment. També és versionada i no-relacional, de manera que ofereix flexibilitat. A més és fàcilment connectable, ja sigui a través de la seva API java o mitjançant web services. Podem fer servir HBase per donar forma a les nostres dades.
Hive
![]()
![]() És una barreja entre MapReduce i HBase. Permet estructurar les dades en taules i vistes i ens permet realitzar tot tipus de consultes usant el seu llenguatge de querying tipus SQL, el HiveQL. Per a aquells casos en què no puguem obtenir el que volem amb HiveQL, podem connectar Hive amb els nostres propis mappers i reducers, ja que Hive és molt flexible quant a connectivitat i se li pot connectar qualsevol cosa.
És una barreja entre MapReduce i HBase. Permet estructurar les dades en taules i vistes i ens permet realitzar tot tipus de consultes usant el seu llenguatge de querying tipus SQL, el HiveQL. Per a aquells casos en què no puguem obtenir el que volem amb HiveQL, podem connectar Hive amb els nostres propis mappers i reducers, ja que Hive és molt flexible quant a connectivitat i se li pot connectar qualsevol cosa.
Spark
![]()
![]() És el rei que ha vingut a conquerir-los a tots. Mentre que MapReduce realitza els seus processos sobre disc, Spark càrrega en memòria les dades i realitza operacions entre datasets intermedis anomenats RDDs. Això fa que el seu rendiment sigui brutal. A més és bastant senzill d’utilitzar i té suport tant per Scala com per Java i Python, comptant amb llibreries per realitzar processament en micro-batch (STREAMING), machine learning (MLLIB), grafs (GRAPH) i SQL (SPARKSQL).
És el rei que ha vingut a conquerir-los a tots. Mentre que MapReduce realitza els seus processos sobre disc, Spark càrrega en memòria les dades i realitza operacions entre datasets intermedis anomenats RDDs. Això fa que el seu rendiment sigui brutal. A més és bastant senzill d’utilitzar i té suport tant per Scala com per Java i Python, comptant amb llibreries per realitzar processament en micro-batch (STREAMING), machine learning (MLLIB), grafs (GRAPH) i SQL (SPARKSQL).
Altres Complements
A més de la suite típica que hem vist, hi ha molts altres productes que funcionen juntament amb Hadoop i permeten noves funcionalitats. Segons el tipus d’aplicació farem servir unes o altres. També existeixen variants d’aquestes eines adaptades a usos específics, com SparkOnHBase, Spork, RHadoop i molts més. Aquí teniu una minúscula classificació:
Data Engineering: Spark, Hive, Pig
Data Discovery & Analytics: Spark, Impala, Solr
Data Integration & Storage: HBase, Kudu, HDFS
Unified Data Services: Yarn, Sentry, Hue, Oozie
Data Ingestion: Sqoop, Flume, Kafka
Hands on
Hem vist només una pinzellada de les eines que es fan servir per Big Data. Dominar-les és qüestió d’hores i de pràctica. Per practicar, podeu fer ús de la VM que anteriorment us comentava per posar en pràctica algun dels molts cursos i tutorials que es poden trobar on-line, com aquest curs gratuït, que t’ensenyaran des de fer el clàssic WordCount fins a realitzar tasques d’Analytics més complexes. També recomano encaridament recórrer als clàssics llibres O’Reilly específics de cada tecnologia.